TLDR:
- I'm working on a relational programming language intended for rapid GUI dev.
- Having tried a couple of different approaches to describing GUIs, I've settled on a React-like library that binds relational data to HTML templates.
- The library has very simple semantics, including an easy mental model for patching the DOM.
- The template language can be implemented almost entirely by compiling to relational queries.
- The current implementation has been used to build a few simple examples, with performance on par with similar libraries in OOPy languages.
Background
The typical architecture for a small web or native app looks like:
datastore (relations) <-> application logic (objects) <-> GUI (trees)
Moving data back and forth between the first two layers is painful because of the object-relational mismatch. Developers typically try to solve this by hiding or getting rid off relations.
But relational data models have a lot of great qualities, so it's interesting to try getting rid off the objects instead by making a datastore query language that can comfortably express the application logic.
But that still leaves us with another data model mismatch - between the relational model in the application logic and the tree model that almost every GUI uses.
datastore + application logic (relations) <-> GUI (trees)
That's what we're going to deal with in this post.
To keep things concrete, we'll use this very simple chat app as a running example.

Yes, it is hideous, but it illustrates all the important cases while being small enough to show large chunks of the internal dataflow.
Imp
Imp is a datalog-ish language in the same family as Eve, LogicBlox, Bloom, Dyna etc.
Imp is focused on reducing the number of layers and concepts involved in writing GUI apps - prioritizing simplicity over scale/power.
The goal is to build apps that run on one machine or that serve small number of users on a local network, and not so much to build public apps that scale to large numbers of users. Think shiny or nitrogen, not rails.
Imp data is stored in relations. The schema is usually highly normalized - this has some important advantages that we will see later.
Here are the relations used in the chat example:
const Session = Int64
const Message = Int64
@relation username(Session) => String
@relation message(Message)
@relation text(Message) => String
@relation sent_by(Message) => String
@relation sent_at(Message) => DateTime
@relation likes(username::String, Message)
And a direct translation into sql:
create table username(session int, username varchar, primary key (session));
create table message(id int, primary key (id));
create table text(id int, text varchar, primary key (id));
create table sent_by(id int, username varchar, primary key (id));
create table sent_at(id int, time timestamp, primary key (id));
create table likes(username varchar, id int, primary key (username, id));
Imp programs are built out of relational queries. Each line within the query refers to a single relation and its columns. Whenever the same variable name is used for more than one column, those columns are joined together. Subqueries begin with @query and return an array of results for each column.
Here is a query that records data for each new message:
@query begin
new_message(session, text)
username(session) => username
@query begin
message(id) => (_, _)
end
new_message = 1 + length(id)
return message(new_message)
return text(new_message) => text
return sent_by(new_message) => username
return sent_at(new_message) => now()
end
And again, a direct translation into sql:
begin;
create temporary table results as (
select new_message.text as text, username.username as username, ((select count(*) from message) + 1) as next_message
from new_message, username
where new_message.session = username.session
);
insert into message select next_message from results;
insert into text select next_message, text from results;
insert into sent_by select next_message, username from results;
insert into sent_at select next_message, now() from results;
commit;
Imp is built on top of Julia. The queries are compiled to Julia code and can use any Julia types and functions. The DateTime type and the now() function used above are part of the Julia standard library.
Previous approaches
In a typical OOPy language we would probably build these trees using a template language like this one:
<table>
{% for message in messages %}
<tr>
<td>{% message.sent_by %}:</td>
<td>{% message.text %}</td>
<td>
{% for like in message.likes %}
<div>{% like.liker %} likes this</div>
{% endfor %}
</td>
<td>
<button onclick="new_like({% session %}, {% message.id %})">
like!
</button>
</td>
</tr>
{% endfor %}
</table>
There are all kinds of template languages, but what they generally have in common is that their visual appearance mimics the mental model of the tree they are producing. This makes them much easier to read and navigate.
In previous versions of Imp, I've tried two different approaches to building trees. Both are pretty hard to follow, so just let your eyes glaze over and see the rough outline.
The first approach was to just use an existing tree datatype and use subqueries and aggregation to build it up:
using Hiccup # virtual DOM library
@relation tree() => Hiccup.Node
@query begin
session(session)
@query begin
message(message)
sent_by(message) => sent_by
text(message) => text
@query begin
likes(liker, message)
like_node = div("$liker likes this")
return like_node
end
message_node = tr(
td(sent_by),
td(text),
td(like_node...),
button(onclick="new_like($session, $message)", "like!")
)
return message_node
end
table_node = table(message_node...)
return tree(session) => table_node
end
The second was to represent the tree as a set of relations, using hashes to create unique node ids:
struct Node
id::UInt64
end
@relation root(Session) => Node
@relation parent(Node) => Node
@relation sort_key(Node) => Any
@relation tag(Node) => String
@relation attribute(Node, String) => String
@query begin
session(session)
table_node = Node(hash(:table, session))
return root(session) => table_node
return tab(table_node) => "table"
end
@query begin
session(session)
message(message)
sent_by(message) => sent_by
text(message) => text
table_node = Node(hash(:table, session))
tr_node = Node(hash(:tr, session, message))
td_node_1 = Node(hash(:td, session, message, 1))
td_node_2 = Node(hash(:td, session, message, 2))
td_node_3 = Node(hash(:td, session, message, 3))
button_node = Node(hash(:button, session, message))
return parent(tr_node) => table_node
return tag(tr_node) => "tr"
return parent(td_node_1) => tr_node
return tag(td_node_1) => "td"
return attribute(td_node_1, "textContent") => sent_by
return sort_key(td_node_1) => 1
return parent(td_node_2) => tr_node
return tag(td_node_2) => "td"
return attribute(td_node_2, "textContent") => text
return sort_key(td_node_2) => 2
return parent(td_node_3) => tr_node
return tag(td_node_3) => "td"
return sort_key(td_node_3) => 3
return parent(button_node) => tr_node
return tag(button_node) => "button"
return attribute(button_node, "textContent") => "like!"
return attribute(button_node, "onclick") => "new_like($session, $message)"
return sort_key(button_node) => 4
end
@query begin
session(session)
likes(liker, message)
td_node_3 = Node(hash(:td, session, message, 4))
liker_node = Node(hash(:like, session, message, liker))
return parent(liker_node) => td_node_3
return tag(liker_node) => "div"
return sort_key(liker_node) => "$liker likes this!"
return attribute(liker_node, "textContent") => liker
end
The extreme verbosity of the second approach can be tamed with a little syntax sugar, but both approaches still suffer from the lack of visual similarity between the code structure and the UI structure.
The core problem is these nested for loops in the OOPy template:
{% for message in messages %}
...
{% for like in message.likes %}
...
{% endfor %}
...
{% endfor %}
We can try to emulate this structure with a relational query:
select message.id, likes.liker
from message, likes
where message.id = likes.message
But this query does not return any results for messages which have no likes. To generate the correct UI tree we have to break this up into multiple queries, use subqueries or use lateral joins. That leads to tangled query code that is hard to visually match up to the resulting tree.
So I created a relational analogue to the OOPy template language, that expresses these nested joins in a way that visually mimics the structure of the resulting HTML tree.
Templates
Imp templates look like this:
[table
@query message(message) begin
[tr
@query sent_by(message) => sent_by begin
[td "$sent_by:"]
end
@query text(message) => text begin
[td "$text"]
end
[td
@query likes(liker, message) begin
[div "$liker likes this!"]
end
]
[td
[button "like!" onclick="new_like($session, $message)"]
]
]
end
]
Templates are made up of four kinds of elements:
- DOM nodes like
[table ...] - DOM attributes like
onclick="new_like($session, $message)" - Text nodes like
"$liker likes this!" - Query fragments like
@query likes(liker, message) begin ... end
Query fragments like @query likes(liker, message) begin ... end acts much like a for loop. For each row in the likes relation, we create a copy of everything between begin and end. But any variables that have already appeared in an enclosing query fragment are already bound to some value, so we keep only the rows that have matching values. In this case, message already appeared the in the enclosing query fragment message(message) begin ... end. The equivalent code in the OOPy template would be {% for like in likes if like.message == message.id %}.
The order the rows appear in is determined by sorting them by their variables in lexicographic order. So rows from likes(liker, message) are sorted first by liker and then by message.
Let's see how this works out in practice. Here is the data behind the screenshot from the beginning of this post:
message(1)
message(2)
message(3)
message(4)
sent_by(1) => "alice"
sent_by(2) => "bob"
sent_by(3) => "chia"
sent_by(4) => "chia"
text(1) => "hello"
text(2) => "hi"
text(3) => "greetings"
text(4) => "free tacos all round!"
likes("alice", 4)
likes("bob", 4)
When we run the query fragments in our templates on this data, we get:
[table
@query message(message=1) begin
[tr
@query sent_by(message=1) => sent_by="alice" begin
[td "$sent_by:"]
end
@query text(message=1) => text="hello" begin
[td "$text"]
end
[td
]
[td
[button "like!" onclick="new_like($session, $message)"]
]
]
end
@query message(message=2) begin
[tr
@query sent_by(message=2) => sent_by="bob" begin
[td "$sent_by:"]
end
@query text(message=2) => text="hi" begin
[td "$text"]
end
[td
]
[td
[button "like!" onclick="new_like($session, $message)"]
]
]
end
@query message(message=3) begin
[tr
@query sent_by(message=3) => sent_by="chia" begin
[td "$sent_by:"]
end
@query text(message=3) => text="greetings" begin
[td "$text"]
end
[td
]
[td
[button "like!" onclick="new_like($session, $message)"]
]
]
end
@query message(message=4) begin
[tr
@query sent_by(message=4) => sent_by="chia" begin
[td "$sent_by:"]
end
@query text(message=4) => text="free tacos all round!" begin
[td "$text"]
end
[td
@query likes(liker="alice", message=4) begin
[div "$liker likes this!"]
end
@query likes(liker="bob", message=4) begin
[div "$liker likes this!"]
end
]
[td
[button "like!" onclick="new_like($session, $message)"]
]
]
end
]
Next we take all the text nodes, such as "$liker likes this!", and replace the $-interpolated variables with their values.
[table
@query message(message=1) begin
[tr
@query sent_by(message=1) => sent_by="alice" begin
[td "alice:"]
end
@query text(message=1) => text="hello" begin
[td "hello"]
end
[td
]
[td
[button "like!" onclick="new_like(42, 1)"]
]
]
end
@query message(message=2) begin
[tr
@query sent_by(message=2) => sent_by="bob" begin
[td "bob:"]
end
@query text(message=2) => text="hi" begin
[td "hi"]
end
[td
]
[td
[button "like!" onclick="new_like(42, 2)"]
]
]
end
@query message(message=3) begin
[tr
@query sent_by(message=3) => sent_by="chia" begin
[td "chia:"]
end
@query text(message=3) => text="greetings" begin
[td "greetings"]
end
[td
]
[td
[button "like!" onclick="new_like(42, 3)"]
]
]
end
@query message(message=4) begin
[tr
@query sent_by(message=4) => sent_by="chia" begin
[td "chia:"]
end
@query text(message=4) => text="free tacos all round!" begin
[td "free tacos all round!"]
end
[td
@query likes(liker="alice", message=4) begin
[div "alice likes this!"]
end
@query likes(liker="bob", message=4) begin
[div "bob likes this!"]
end
]
[td
[button "like!" onclick="new_like(42, 4)"]
]
]
end
]
Now that the interpolated variables have been filled in we don't need the query fragments anymore, so they are each removed and replaced by their children, yielding our final DOM tree:
[table
[tr
[td "alice:"]
[td "hello"]
[td
]
[td
[button "like!" onclick="new_like(42, 1)"]
]
]
[tr
[td "bob:"]
[td "hi"]
[td
]
[td
[button "like!" onclick="new_like(42, 2)"]
]
]
[tr
[td "chia:"]
[td "greetings"]
[td
]
[td
[button "like!" onclick="new_like(42, 3)"]
]
]
[tr
[td "chia:"]
[td "free tacos all round!"]
[td
[div "alice likes this!"]
[div "bob likes this!"]
]
[td
[button "like!" onclick="new_like(42, 4)"]
]
]
]
Patching
As described so far, this is only good for one-off rendering. We need to define what happens when the underlying data changes. Suppose Alice retracts her liking of free tacos, Bob deletes his message entirely and Chia sends a new message complaining about their fickleness.
message(1)
-message(2)
message(3)
message(4)
+message(5)
sent_by(1) => "alice"
-sent_by(2) => "bob"
sent_by(3) => "chia"
sent_by(4) => "chia"
+sent_by(5) => "chia"
text(1) => "hello"
-text(2) => "hi"
text(3) => "greetings"
text(4) => "free tacos all round!"
+text(5) => "who doesn't like free tacos?"
-likes("alice", 4)
likes("bob", 4)
With the new data, the template now specifies this DOM tree:
[table
[tr
[td "alice:"]
[td "hello"]
[td
]
[td
[button "like!" onclick="new_like(42, 1)"]
]
]
[tr
[td "chia:"]
[td "greetings"]
[td
]
[td
[button "like!" onclick="new_like(42, 3)"]
]
]
[tr
[td "chia:"]
[td "free tacos all round!"]
[td
[div "bob likes this!"]
]
[td
[button "like!" onclick="new_like(42, 4)"]
]
]
[tr
[td "chia:"]
[td "who doesn't like free tacos?"]
[td
]
[td
[button "like!" onclick="new_like(42, 5)"]
]
]
]
Obviously, we want to guarantee that changes are made to the DOM in the browser so that the end result matches the new results from the template.
But it's not enough to specify only the end result. Some DOM nodes have their own state that is not reflected in the template, such as scroll position or text entered by the user. It's not practical to manage this state from the server, both because of the latency involved and the inability to block the client or save up keystrokes. But deleting and recreating a node will erase its state. So as part of the semantics of the template library we have to specify exactly what changes it makes to the DOM on the way to the correct end result.
Libraries like React do this by specifying an algorithm that compares the old and new DOM trees and computes a set of changes that will turn one into the other. When comparing large lists of elements, it recommends that users supply a unique key for each element to help React decide whether to mutate an old list element or delete and replace it. It warns:
It is important to remember that the reconciliation algorithm is an implementation detail... We are regularly refining the heuristics in order to make common use cases faster.
Keys should be stable, predictable, and unique. Unstable keys ... will cause many component instances and DOM nodes to be unnecessarily recreated, which can cause performance degradation and lost state in child components.
Given that varying the heuristics can result in lost state in child components, I'm reluctant to endorse describing them as an implementation detail. But it's difficult for React to do much better because the mapping from data to virtual DOM is defined by opaque javascript code.
In our templates we have much better information about how data maps to the filled out template, so we can adopt a much simpler set of rules:
- When a new row is added to a relation, everything under the corresponding query fragment is created from scratch.
- When a row is removed from a relation, everything under the corresponding query fragment is deleted.
Updating a row is the same as removing the old row and adding the new row. Since the schema is so heavily normalized this generally doesn't affect any values other than the one that was changed.
So if the change to our data is:
message(1)
-message(2)
message(3)
message(4)
+message(5)
sent_by(1) => "alice"
-sent_by(2) => "bob"
sent_by(3) => "chia"
sent_by(4) => "chia"
+sent_by(5) => "chia"
text(1) => "hello"
-text(2) => "hi"
text(3) => "greetings"
text(4) => "free tacos all round!"
+text(5) => "who doesn't like free tacos?"
-likes("alice", 4)
likes("bob", 4)
Then the change to the DOM will be:
[table
[tr
[td "alice:"]
[td "hello"]
[td
]
[td
[button "like!" onclick="new_like(42, 1)"]
]
]
- [tr
- [td "bob:"]
- [td "hi"]
- [td
- ]
- [td
- [button "like!" onclick="new_like(42, 2)"]
- ]
- ]
[tr
[td "chia:"]
[td "greetings"]
[td
]
[td
[button "like!" onclick="new_like(42, 3)"]
]
]
[tr
[td "chia:"]
[td "free tacos all round!"]
[td
- [div "alice likes this!"]
[div "bob likes this!"]
]
[td
[button "like!" onclick="new_like(42, 4)"]
]
]
+ [tr
+ [td "chia:"]
+ [td "who doesn't like free tacos?"]
+ [td
+ ]
+ [td
+ [button "like!" onclick="new_like(42, 5)"]
+ ]
+ ]
]
That is, we delete the [tr ...] subtree containing Bobs message, we delete the [div ...] containing Alices like and we create a new subtree for Chias new message.
That may seem obvious, but we could just as correctly have decided to leave the four message subtrees intact but change the text of each. Without unique keys to help match up the old and new subtrees, React might decide to do exactly that.
Tying the identity of each subtree to the rows that feed them data provides a simple mental model that is easy to map to the visual appearance of the template.
Events
We also need to be able to react to user input.
In Imp, we can tag relations as event relations:
@event new_like(Session, Message)
For every event relation, a matching javascript function is created that will insert a row into that relation. Event handlers in the template can call these functions to send data back to the server.
[button "like!" onclick="new_like($session, $message)"]
And then we can write Imp queries to react to these events:
@query begin
new_like(session, message)
username(session) => username
return likes(username, message)
end
We also still allow arbitrary javascript in event handlers, which is useful for eg reading state from the DOM.
[input
style="width: 100%; height: 2em"
placeholder="What do you want to say?"
onkeydown="if (event.which == 13) {new_message($session, this.value); this.value=''}"
]
Again, if this was running in the browser itself or we were using a native UI toolkit it might be useful to manage such state directly. But in the current server/client implementation it's more practical to leave low-latency interactions such as typing and scrolling to the browser.
Sessions
We give each browser tab a unique session key. The template is implicitly wrapped in @query session(session) begin ... end so that it can behave differently for each session.
For example, when someone clicks like! we record their session id so we can later display their username in the likes list.
[button "like!" onclick="new_like($session, $message)"]
Implementation
As much as possible we want to do the work in Imp queries. This lets us take advantage of the query compiler for efficient joins. It also means that when I get around to implementing incremental view maintenance, I'll get incremental template evaluation for free.
Let's walk through how the template compiler deals with our example.
The first thing the compiler does is number all the nodes (in pre-order) to make it easier to refer to them.
[table # 1
@query message(message) begin # 2
[tr # 3
@query sent_by(message) => sent_by begin # 4
[td "$sent_by:"] # 8
end
@query text(message) => text begin # 5
[td "$text"] # 9
end
[td # 6
@query likes(liker, message) begin # 10
[div "$liker likes this!"] # 12
end
]
[td # 7
[button "like!" onclick="new_like($session, $message)"] # 11
]
]
end
]
Next, for each query fragment we create a corresponding query that performs a join against all the data produced by the enclosing queries. We also create an id for each filled out query fragment by hashing together the node id and all the variable values. (This id is just used as a shorthand reference - if hash collisions are worrying you could use some kind of lookup table or even just use the list of variable values directly.)
@query begin # special dummy query for the root of the tree
session(session)
return query_0(session) => hash(session)
end
@query begin
query_0(session) => query_parent_hash
message(message)
my_hash = hash(message, hash(2, query_parent_hash))
return query_2(session, message) => my_hash
end
@query begin
query_2(session, message) => query_parent_hash
sent_by(message, sent_by)
my_hash = hash(sent_by, hash(message, hash(4, query_parent_hash)))
return query_4(session, message, sent_by) => my_hash
end
@query begin
query_2(session, message) => query_parent_hash
text(message, text)
my_hash = hash(text, hash(message, hash(5, query_parent_hash)))
return query_5(session, message, text) => my_hash
end
@query begin
query_2(session, message) => query_parent_hash
likes(liker, message)
my_hash = hash(message, hash(liker, hash(10, query_parent_hash)))
return query_10(session, message, liker) => my_hash
end
When we run these queries on the original data, we get something like this (but with real hashes):
query_0(42) => 0x00
query_2(42, 1) => 0x01
query_2(42, 2) => 0x02
query_2(42, 3) => 0x03
query_2(42, 4) => 0x04
query_4(42, 1, "alice") => 0x05
query_4(42, 2, "bob") => 0x06
query_4(42, 3, "chia") => 0x07
query_4(42, 4, "chia") => 0x08
query_5(42, 1, "hello") => 0x09
query_5(42, 2, "hi") => 0x10
query_5(42, 3, "greetings") => 0x11
query_5(42, 4, "free tacos all round!") => 0x12
query_10(42, 4, "alice") => 0x13
query_10(42, 4, "bob") => 0x14
Next we need to calculate what order the remaining nodes will be in after the query fragments are removed. Doing this in a way that is amenable to efficient incremental maintenance is tricky eg if we just calculate positions of each child within its parent, inserting one child would mean updating the positions of all the children that came after it.
But I eventually hit upon an elegant solution. The position of each node can be described by the positions and variable values of all the query nodes between it and its eventual parent:
# --- template ---
[table # 1
@query message(message) begin # 2
[tr # 3
@query sent_by(message) => sent_by begin # 4
[td "$sent_by:"] # 8
end
@query text(message) => text begin # 5
[td "$text"] # 9
end
[td # 6
@query likes(liker, message) begin # 10
[div "$liker likes this!"] # 12
end
]
[td # 7
[button "like!" onclick="new_like($session, $message)"] # 11
]
]
end
]
# --- filled out template ---
[table # node 1
@query message(message=1) begin
[tr # 1st child of node 1 -> 1st child of node 2 -> message=1
@query sent_by(message=1) => sent_by="alice" begin
[td "alice:"] # 1st child of node 1 -> 1st child of node 2 -> message=1 -> 1st child of node 3 -> sent_by="alice" -> 1st child of node 4
end
@query text(message=1) => text="hello" begin
[td "hello"] # 1st child of node 1 -> 1st child of node 2 -> message=1 -> 2nd child of node 3 -> text="hello" -> 1st child of node 5
end
[td # 1st child of node 1 -> 1st child of node 2 -> message=1 -> 3rd child of node 3
]
[td # 1st child of node 1 -> 1st child of node 2 -> message=1 -> 4th child of node 3
[button "like!" onclick="new_like(42, 1)"] # 1st child of node 1 -> 1st child of node 2 -> message=1 -> 4th child of node 3 -> 1st child of node 7
]
]
end
# etc...
]
(A potential confusion - when we say "nth child of node x" we mean the nth child in the template, not in the resulting DOM tree. We can't use the positions in the DOM tree because those are exactly what we are trying to calculate.)
If we represent these paths as tuples and use them as sort keys, the nodes at each level will end up sorted in the correct order:
(1, 1, message=1, 1, sent_by="alice") => [td "alice:"]
(1, 1, message=1, 2, text="hello") => [td "hello"]
(1, 1, message=1, 3) => [td]
(1, 1, message=1, 4) => [td [button "like!" onclick="new_like(42, 1)"]]
When we insert new nodes around an existing one its key doesn't change, so whatever incremental maintenance algorithm I end up using will only have to deal with inserting and deleting rows for each node and not updating any additional bookkeeping information elsewhere.
Julia can avoid dynamic dispatch when given stable types. To make sure all the sort keys have the same type, we can just fill in dummy columns.
(1, 1, message=1, 1, sent_by="alice", text="") => [td "alice:"]
(1, 1, message=1, 2, sent_by="", text="hello") => [td "hello"]
(1, 1, message=1, 3, sent_by="", text="") => [td]
(1, 1, message=1, 4, sent_by="", text="") => [td [button "like!" onclick="new_like(42, 1)"]]
Now for each DOM node in the template we create a query that calculates the correct sort key, as well as the node id, the parent node id, the type of DOM node and the content.
@query begin
query_0(session) => query_hash
my_hash = hash(0, query_hash)
return group_0(session, 1) => (UInt64(0), my_hash, Html, "table")
end
@query begin
query_2(session, message) => query_parent_hash
group_0(session, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(3, query_parent_hash)
return group_1(session, 1, message, 1) => (fixed_parent_hash, my_hash, Html, "tr")
end
@query begin
query_4(session, message, sent_by) => query_parent_hash
group_1(session, 1, message, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(8, query_parent_hash)
return group_3(session, message, 1, sent_by, 1, "", 0) => (fixed_parent_hash, my_hash, Html, "td")
end
@query begin
query_5(session, message, text) => query_parent_hash
group_1(session, 1, message, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(9, query_parent_hash)
return group_3(session, message, 2, "", 0, text, 1) => (fixed_parent_hash, my_hash, Html, "td")
end
@query begin
query_2(session, message) => query_parent_hash
group_1(session, 1, message, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(6, query_parent_hash)
return group_3(session, message, 3, "", 0, "", 0) => (fixed_parent_hash, my_hash, Html, "td")
end
@query begin
query_2(session, message) => query_parent_hash
group_1(session, 1, message, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(7, query_parent_hash)
return group_3(session, message, 4, "", 0, "", 0) => (fixed_parent_hash, my_hash, Html, "td")
end
@query begin
query_4(session, message, sent_by) => query_parent_hash
group_3(session, message, 1, sent_by, 1, _, 0) => (_, fixed_parent_hash, _, _)
my_hash = hash(11, query_parent_hash)
return group_8(session, message, sent_by, 1) => (fixed_parent_hash, my_hash, Text, string(sent_by, ":"))
end
@query begin
query_5(session, message, text) => query_parent_hash
group_3(session, message, 2, _, 0, text, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(12, query_parent_hash)
return group_9(session, message, text, 1) => (fixed_parent_hash, my_hash, Text, string(text))
end
@query begin
query_2(session, message) => query_parent_hash
group_3(session, message, 4, _, 0, _, 0) => (_, fixed_parent_hash, _, _)
my_hash = hash(13, query_parent_hash)
return group_7(session, message, 1) => (fixed_parent_hash, my_hash, Html, "button")
end
@query begin
query_10(session, message, liker) => query_parent_hash
group_3(session, message, 3, _, 0, _, 0) => (_, fixed_parent_hash, _, _)
my_hash = hash(14, query_parent_hash)
return group_6(session, message, 1, liker, 1) => (fixed_parent_hash, my_hash, Html, "div")
end
@query begin
query_2(session, message) => query_parent_hash
group_7(session, message, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(15, query_parent_hash)
return group_13(session, message, 1) => (fixed_parent_hash, my_hash, Text, "like!")
end
@query begin
query_10(session, message, liker) => query_parent_hash
group_6(session, message, 1, liker, 1) => (_, fixed_parent_hash, _, _)
my_hash = hash(17, query_parent_hash)
return group_14(session, message, liker, 1) => (fixed_parent_hash, my_hash, Text, string(liker, " likes this!"))
end
When we run these queries on the original data, we get something like this (but with real hashes):
group_0(42, 1) => (0x00, 0x01, Html, "table")
group_1(42, 1, 1, 1) => (0x01, 0x02, Html, "tr")
group_1(42, 1, 2, 1) => (0x01, 0x03, Html, "tr")
group_1(42, 1, 3, 1) => (0x01, 0x04, Html, "tr")
group_1(42, 1, 4, 1) => (0x01, 0x05, Html, "tr")
group_3(42, 1, 1, "alice", 1, "", 0) => (0x02, 0x06, Html, "td")
group_3(42, 1, 2, "", 0, "hello", 1) => (0x02, 0x07, Html, "td")
group_3(42, 1, 3, "", 0, "", 0) => (0x02, 0x08, Html, "td")
group_3(42, 1, 4, "", 0, "", 0) => (0x02, 0x09, Html, "td")
group_3(42, 2, 1, "bob", 1, "", 0) => (0x03, 0x10, Html, "td")
group_3(42, 2, 2, "", 0, "hi", 1) => (0x03, 0x11, Html, "td")
group_3(42, 2, 3, "", 0, "", 0) => (0x03, 0x12, Html, "td")
group_3(42, 2, 4, "", 0, "", 0) => (0x03, 0x13, Html, "td")
group_3(42, 3 1, "chia", 1, "", 0) => (0x04, 0x14, Html, "td")
group_3(42, 3 2, "", 0, "greetings", 1) => (0x04, 0x15, Html, "td")
group_3(42, 3, 3, "", 0, "", 0) => (0x04, 0x16, Html, "td")
group_3(42, 3, 4, "", 0, "", 0) => (0x04, 0x17, Html, "td")
group_3(42, 4, 1, "chia", 1, "", 0) => (0x05, 0x18, Html, "td")
group_3(42, 4, 2, "", 0, "free tacos all round!", 1) => (0x05, 0x19, Html, "td")
group_3(42, 4, 3, "", 0, "", 0) => (0x05, 0x20, Html, "td")
group_3(42, 4, 4, "", 0, "", 0) => (0x05, 0x21, Html, "td")
# etc...
Now we have a list of every DOM node together with a (probably) unique id and the id of its parent node. Since they are sorted in the correct order we can also easily find the siblings of each node. That will come in handy later when we patch the DOM tree.
DOM attributes like onclick="new_like($session, $message)" are handled similarly to DOM nodes, except that their order doesn't matter so there is no sort key.
@query begin
query_2(session, message) => _
group_7(session, message, 1) => (_, fixed_parent_hash, _, _)
return attribute_16(session, fixed_parent_hash, "onclick") => string("new_like(", session, ", ", message, ")")
end
Now lets consider again what happens when our source data changes:
message(1)
-message(2)
message(3)
message(4)
+message(5)
sent_by(1) => "alice"
-sent_by(2) => "bob"
sent_by(3) => "chia"
sent_by(4) => "chia"
+sent_by(5) => "chia"
text(1) => "hello"
-text(2) => "hi"
text(3) => "greetings"
text(4) => "free tacos all round!"
+text(5) => "who doesn't like free tacos?"
-likes("alice", 4)
likes("bob", 4)
This results in downstream changes in the compiled queries:
group_0(42, 1) => (0x00, 0x01, Html, "table")
group_1(42, 1, 1, 1) => (0x01, 0x02, Html, "tr")
-group_1(42, 1, 2, 1) => (0x01, 0x03, Html, "tr")
group_1(42, 1, 3, 1) => (0x01, 0x04, Html, "tr")
group_1(42, 1, 4, 1) => (0x01, 0x05, Html, "tr")
+group_1(42, 1, 5, 1) => (0x01, 0x22, Html, "tr")
group_3(42, 1, 1, "alice", 1, "", 0) => (0x02, 0x06, Html, "td")
group_3(42, 1, 2, "", 0, "hello", 1) => (0x02, 0x07, Html, "td")
group_3(42, 1, 3, "", 0, "", 0) => (0x02, 0x08, Html, "td")
group_3(42, 1, 4, "", 0, "", 0) => (0x02, 0x09, Html, "td")
-group_3(42, 2, 1, "bob", 1, "", 0) => (0x03, 0x10, Html, "td")
-group_3(42, 2, 2, "", 0, "hi", 1) => (0x03, 0x11, Html, "td")
-group_3(42, 2, 3, "", 0, "", 0) => (0x03, 0x12, Html, "td")
-group_3(42, 2, 4, "", 0, "", 0) => (0x03, 0x13, Html, "td")
group_3(42, 3, 1, "chia", 1, "", 0) => (0x04, 0x14, Html, "td")
group_3(42, 3, 2, "", 0, "greetings", 1) => (0x04, 0x15, Html, "td")
group_3(42, 3, 3, "", 0, "", 0) => (0x04, 0x16, Html, "td")
group_3(42, 3, 4, "", 0, "", 0) => (0x04, 0x17, Html, "td")
group_3(42, 4, 1, "chia", 1, "", 0) => (0x05, 0x18, Html, "td")
group_3(42, 4, 2, "", 0, "free tacos all round!", 1) => (0x05, 0x19, Html, "td")
group_3(42, 4, 3, "", 0, "", 0) => (0x05, 0x20, Html, "td")
group_3(42, 4, 4, "", 0, "", 0) => (0x05, 0x21, Html, "td")
+group_3(42, 5, 1, "chia", 1, "", 0) => (0x22, 0x23, Html, "td")
+group_3(42, 5, 2, "", 0, "who doesn't like free tacos?", 1) => (0x22, 0x24, Html, "td")
+group_3(42, 5, 3, "", 0, "", 0) => (0x22, 0x25, Html, "td")
+group_3(42, 5, 4, "", 0, "", 0) => (0x22, 0x26, Html, "td")
# etc...
First, for each old node that is not in the new output we instruct the browser to delete the node.
deleteNode(0x03)
deleteNode(0x10)
deleteNode(0x11)
deleteNode(0x12)
deleteNode(0x13)
# etc...
Second, for each new node that is not in the old output we find its sibling, if it has one, and instruct the browser to create the new node and insert it in the appropriate place.
insertAtEnd(0x22, Html, "tr")
insertAtEnd(0x26, Html, "td")
insertBefore(0x26, 0x25, Html, "td")
insertBefore(0x25, 0x24, Html, "td")
insertBefore(0x24, 0x23, Html, "td")
# etc...
The nodes in each group are sorted in the order they will appear in the DOM and the groups themselves are sorted in depth-first order, so if we generate these instructions by order of group and then reverse order within the group, we can be sure that by the time each instruction is run the parent and sibling will always exist.
(What about html escaping? Well, the only way we ever create DOM nodes is via document.createElement or document.createTextNode so injection attacks are not possible there. It is currently possible to inject javascript into interpolated values in event handlers. I plan to deal with that by jsonifying data before interpolating it into javascript strings.)
Expressiveness
All the examples in this post only spliced data into text nodes, but the implementation allows splicing anywhere:
@query dynamic_tag(tag) begin
["$tag"
@query dynamic_attributes(key, val) begin
"$key"="$val"
end
]
end
The templates are just Julia ASTs, so it's possible to create components using ordinary Julia code:
template = quote
[table
@query message(message) begin
[tr
$(message_template(:message)...)
$(likes_template(:message))
[td
[button "like!" onclick="new_like($session, $message)"]
]
]
end
]
end
function message_template(message)
quote [
@query sent_by($message) => sent_by begin
[td "$sent_by:"]
end
@query text($message) => text begin
[td "$text"]
end
] end
end
function likes_template(message)
quote
[td
@query likes(liker, $message) begin
[div "$liker likes this!"]
end
]
end
end
It should be trivial to provide a macro that makes the syntax more direct.
Currently templates are limited to a fixed depth, so they can't express eg a file browser where the depth depends on the data. Allowing components to include themselves recursively would fix this, but it's non-obvious how to combine recursion with the query-based implementation I described earlier. It's probably not impossible, but I won't attempt to deal with it until I definitely need it.
Performance
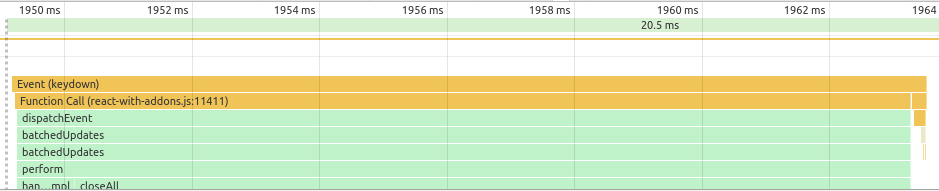
I won't know for sure how well this will perform until I've built something more substantial, but for early feedback I ran some simple timings on the Todomvc example and compared it the official React implementation and some old Om implementation. This is not intended to be a pissing contest - I'm just trying to get a handle on whether performance is likely to be a problem.
My approach is not particularly rigorous. I just ran through all the benchmarks a few times to warmup, and then recorded a profile and eyeballed the time from the user event until the start of layout/rendering/painting.
Imp does all the hard work on the server, so its profiles just show the initial message send and then the patching at the end. React does all the work at once, leading to single long trace. Om does some work to update the app model, and then calculates the diff and patches the DOM on the next animation frame, resulting in two traces.
Times in ms:
| adding 1st todo | adding 200 todos at once | adding 201st todo | |
|---|---|---|---|
| imp | 10 | 22 | 12 |
| react | 6 | x | 14 |
| om | 5 | 100 | 28 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(I couldn't be bothered to download and compile the React version myself to add a button to add 200 todos at once.)
I won't bother reading too much detail into those numbers, but it's clear that Imp is at least in the same ballpark as React and Om for this simple example, which means that this approach could feasibly work.
I also tested how the server scales with multiple sessions connected. This table shows the total time taken by the server to add the 201st todo and update every client (mean of 100 runs).
| tabs | time (ms) |
|---|---|
| 1 | 9 |
| 10 | 22 |
| 100 | 168 |
| 1000* | 2056 |
(*Chrome has a cunning optimization where after ~150 tabs it just stops loading pages, so the last row is 100 real tabs and 900 fake sessions.)
This is the cost to recalculate everything from scratch and is not proportional to the number of events processed, so if I add some kind of event batching it looks like I could handle up to 100 clients with reasonable latency.
Breaking down the costs at 100 tabs:
-
The marginal cost per tab is about 1.6ms. The bulk of the time is spent sorting and resorting relations, rather than solving queries.
-
The marginal allocation rate per tab is 1mb across 5373 allocations. This is almost entirely in the template queries. Most of the individual allocations are from creating identical event strings on each of 200 todos x 100 tabs, but the bulk of the allocation size is from many, many copies of the columns in these relations.
So there is probably a lot of margin for improvement in the control flow layer that binds the queries together and handles sorting/indexing relations. Which is unsurprising, because one of the top items on my todo list is control flow is a pile of poop - make it not that.
Bear in mind also that this is recalculating the UI for each tab from scratch on each event. The UI calculation is built up entirely out of simple joins and maps so in theory it should be easy to maintain incrementally.
Overall, I'm pleasantly surprised that it's already this fast.
Status
The current implementation is not pretty, but it works well enough to demonstrate that this is feasible for simple examples.
I targeted the browser purely for familiarity. The same approach should work with native UI toolkits too, and I may well switch in the future.
Running everything on the server has obvious limitations wrt latency and maximum load. I think this approach could be scaled to handle public webapps with many users, but it would require a much more sophisticated implementation, with some way to run parts of the logic on the client.
I haven't given much thought to security yet. A good start would be to track what events are present in the template and refuse to allow clients to submit any events that aren't on the list.
The implementation strategy here produces non-recursive views which only use simple joins, string concatenation and hashing. It should be possible to target pretty much any relational system. Eg I've implemented the underlying layers in LogicBlox and I'm just waiting on some upcoming features before doing the work to compile templates automatically.
Thanks to rtnz for extensive feedback on the first drafts.