why compile queries?
Database query engines used to be able to assume that disk latency was so high that the overhead of interpreting the query plan didn't matter. Unfortunately these days a cheap nvme ssd can supply data much faster than a query interpreter can process it.
The problem is that most of the cpu time is spent on the overhead of the interpreter itself - figuring out which operator is next, moving data between operators etc - rather than on the actual computation of the query. Depending on the query, removing the interpreter bottleneck can yield several orders of magnitude speedup.
For OLAP-ish queries, which tend to consist of summarizing data via full table scans over compressed column-oriented data, the standard solution is to 'vectorize' the interpreter - run each operator on a batch of rows instead of a single row. Then we only have to pay the interpreter overhead per batch rather than per row. This is a really well understood design and the industry is converging towards a standard set of data formats (eg arrow) and libraries (eg datafusion, velox) that work more or less out of the box.
For OLTP-ish queries, which tend to consist of searching and connecting sparse data using index lookups and hash-joins over row-oriented storage, vectorization doesn't work as well because the inner loop of each operator still has to have dynamic parameters specifying how long a row is and how to extract the value we're operating on. We can't pull that interpreter overhead out because there are an infinite number of possible combinations of parameters.
Instead some OLTP databases (eg sqlserver, singlestore, redshift, oracle) compile queries to native code where those parameters can be hard-coded, allowing the values in each row to be kept in individual cpu registers throughout an entire pipeline.
Compiling queries also makes it easier to integrate external functions, foreign data wrappers, and procedural languages like PL/pgSQL directly into the generated query code, rather than trying to figure out how to vectorize code you didn't write.
But where vectorized interpreters are becoming a commoditized component, each query compiler is a beautiful snowflake written from scratch. They are also kinda going out of fashion for reasons we'll get into below.
why not compile queries?
Compiling a query is a bit different from compiling a regular program. Typically a program is compiled once and then run many times, so it's worth spending a lot of time on optimization at compile-time to save time/money/energy at runtime. But a query might only be run once, so it's only worth spending time on optimizations at compile-time if doing so will save even more time at runtime.
This is hard to get right! We see various workarounds:
- Make the user manually specify which queries to compile.
- Try to estimate at planning time whether query compilation is worthwhile.
- Start running the query in an interpreter and switch to the compiled program when it's ready.
But it's hard to avoid the core dilemma that interpreters run really slowly and llvm compiles really slowly, so we're navigating around a very sharp and abrupt tradeoff. This creates unpredictable performance cliffs.
For example, a few years ago postgres added a jit compiler for scalar expressions. This update crashed the uk coronavirus dashboard! Aws and azure now completely disable the jit compiler by default.
Databases can cache the result of compiling a query but it doesn't fully solve the compile-time problem. Consider these two queries:
SELECT * FROM movies WHERE language = 'english' AND country = 'usa'SELECT * FROM movies WHERE language = 'swahili' AND country = 'spain'
The first query will return a substantial fraction of the database and is probably best planned as a table scan. The second query will return a tiny number of results and is probably best planned as an index lookup on language. So even though the two queries have the same structure, different parameters can produce different plans, which means we have to compile different code.
So even for OLTP workloads many databases still opt for vectorized interpreters instead of compilers, especially in recent years. There is a general perception that vectorized interpreters are easier to build and debug, and produce more predictable performance.
meanwhile in browserland
The other big place where people care about the sum of compile-time and runtime is in the browser when executing javascript/wasm. All the browsers have settled on fairly similar architectures which look roughly like:
- An interpreter, which operates either directly over the ast or over a simple bytecode.
- A baseline compiler, which focuses on emitting code as quickly as possible in a single pass.
- An optimizing compiler, which performs traditional compiler optimizations.
Programs begin running in the interpreter and then switch to compiled code when it's available.
The details vary, of course. Some browsers can only switch to compiled code at function call boundaries whereas others are able to switch in the middle of a function (eg during a long-running loop). Javascript backends tend to only optimize hot functions, whereas wasm backends are more likely to run all functions through at least the baseline compiler. But the overall shape is the same.
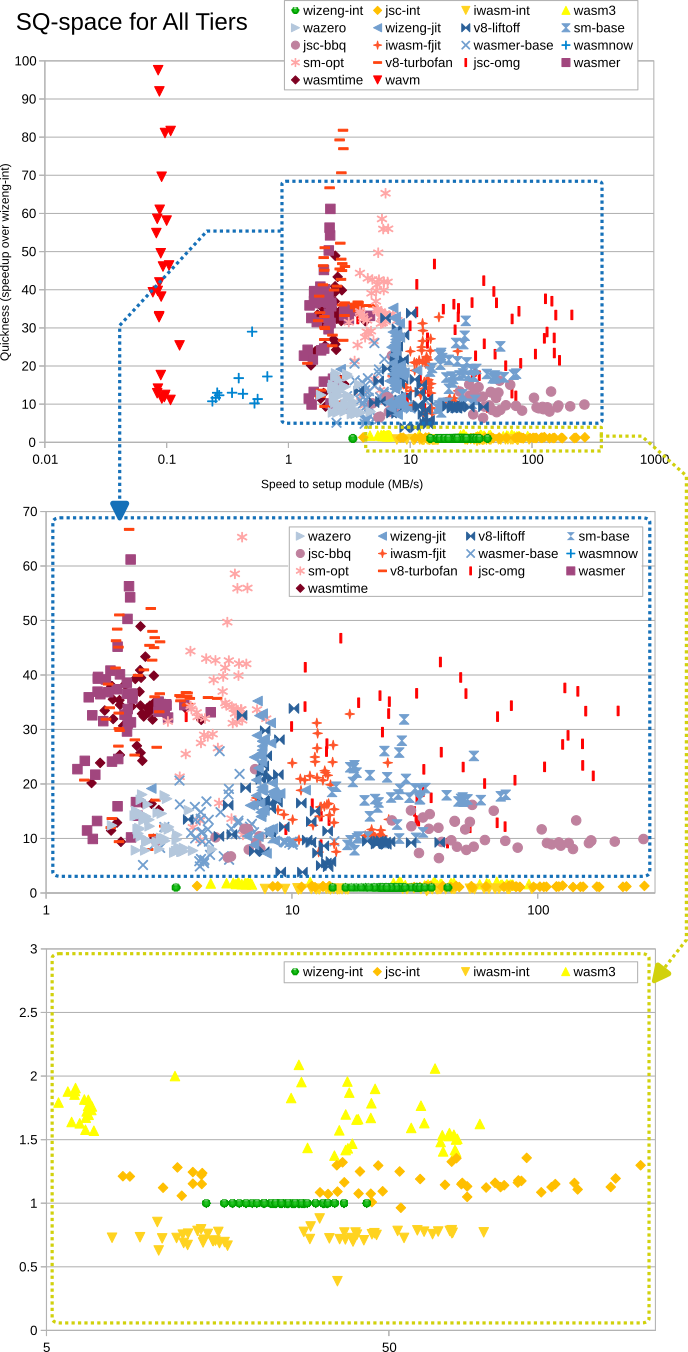
The result is a smooth tradeoff curve with no sudden cliffs, as shown in the graph below from Ben Titzer's paper on wasm backends. The red triangles way out on the left are using llvm and the yellow/orange/green dots at the bottom are interpreteres. You can see how the additional tiers in the blue box fill out the tradeoff space - this is what query compilers are missing.
As far as I know, the only production-quality database that has a baseline compiler is umbra/cedar (EDIT singlestore has compile_lite mode which I'm told is a baseline compiler using asmjit). Their recent paper reports that the tradeoff curve is really sharp around their baseline compiler (DirectEmit) and that their llvm backend is only the best choice for long-running queries:
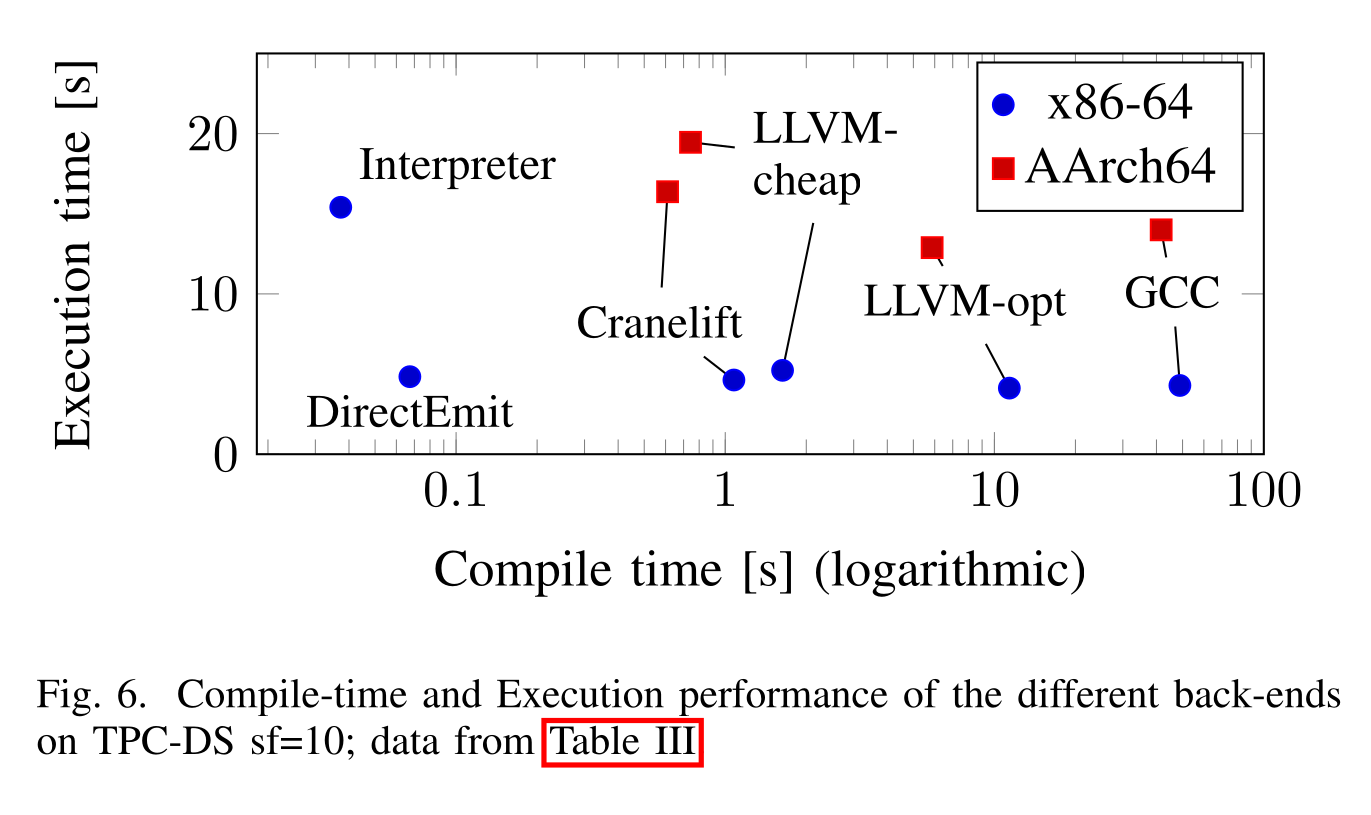
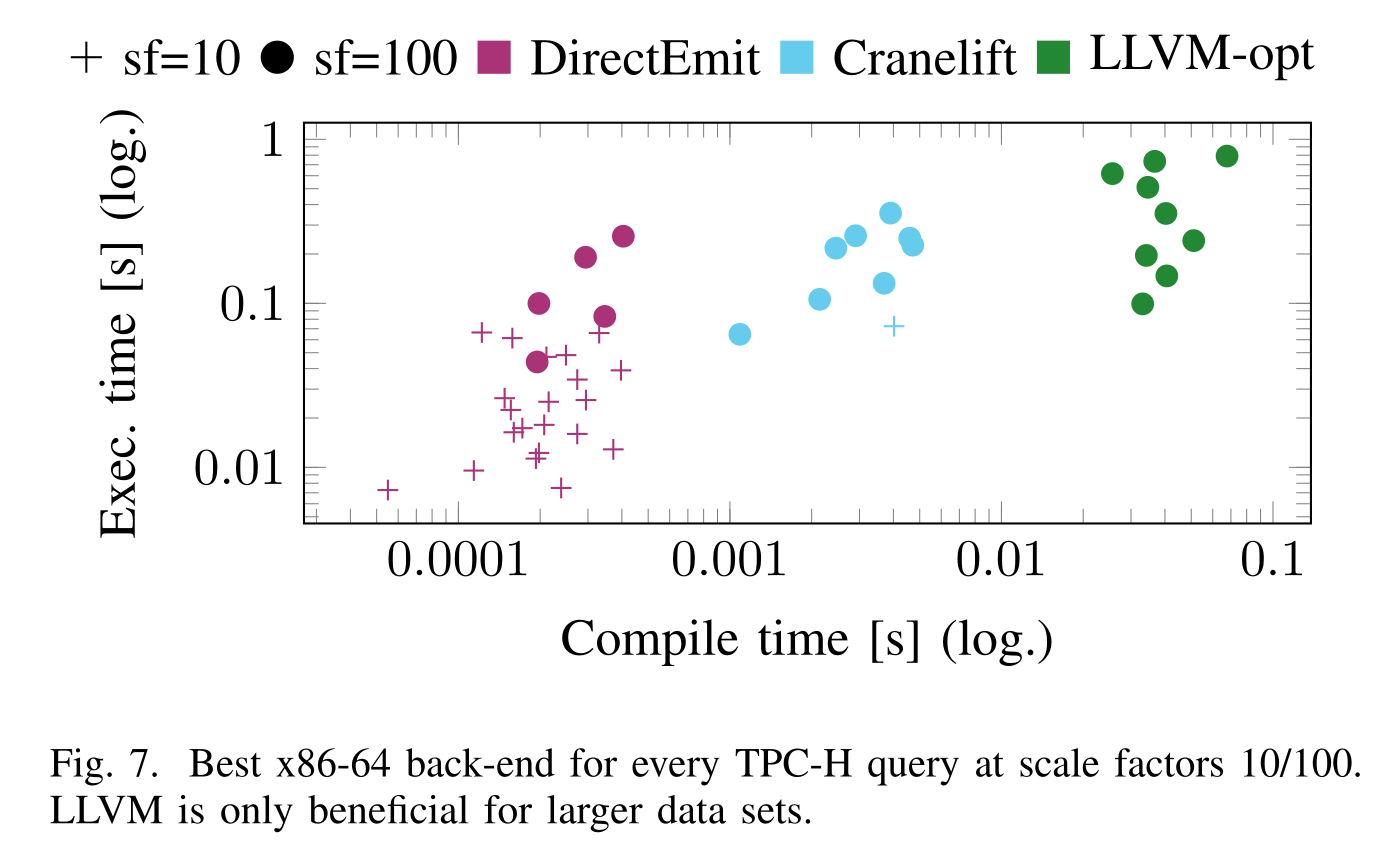
(It's worth noting that umbra's llvm backend still disables most optimization passes to keep compile-time under control. They also demonstrate that llvm's compile times are often super-linear in the size of the function, which is a problem because query compilers like to compile entire pipelines into a single function in order to keep hot values in registers.)
Cedar is not available at the time of writing, so we can't try to reproduce their results on a wider range of benchmarks. But I think it is compelling that browsers operate under similar compile-time constraints and arrived at similar solutions.
hot commodity
Interpreters are easy to build. Optimizing compiler backends are hard to build but are commoditized (llvm, cranelift). I'll argue that baseline compiler backends are not commoditized, but are probably relatively easy to build. But I only have indirect evidence for both claims.
There are a number of open-source jit compiler libraries (eg libjit, llvm-orc, truffle, mir). But it seems that successful projects which care about latency don't use them. All the wasm baseline compilers in the graph above have custom backends. All the major js baseline compilers have custom backends. The jvm has a custom backend. Luajit has a custom backend. The new python jit has a custom copy-and-patch backend.
There have been many many ruby jits using many different backends but the one that is seeing serious production usage is yjit which focuses on predictably low latency using their own custom backend.

So I'm not seeing any real success stories for open-source libraries.
(Especially not for meta-tracing jits - the purple line in the graph above is truffle-ruby and I've heard similar complaints of unpredictable behaviour for pypy/rpython.)
To get a very rough ballpark for implementation effort we can look at lines of code.
Umbra report 30kloc for their entire compiler, of which the actual codegen seems to be 4kloc, and the IR 3kloc. The whole of yjit is 35kloc, of which 17kloc is the ir and codegen. In javascriptcore wasm/WasmBBQ* is 18kloc, but we should probably also count the 57kloc in assembler/. In spidermonkey wasm/WasmBC* is 11kloc, but I'm not sure what else it depends on.
Datafusion is a little tricky because they mix code and unit tests in the same file, but if I delete everything after mod test then I get 12kloc for physical-expr/src/ and 49kloc for functions*/src. For velox if I delete all directories named tests|benchmarks|examples|fuzzer then I get 60kloc for exec/ and 80kloc for functions/.
This kind of comparison is always fraught because it's hard to know what to include without being familiar with a codebase, and we're comparing projects with different maturity and scope (in particular datafusion/velox probably support a lot more sql functions than umbra, which is why I tried to separate out those counts). But I think we can at least take it as weak evidence that writing a baseline compiler is probably not orders of magnitude harder than writing a vectorized interpreter.
take a shortcut?
In some ways writing a baseline compiler for a query engine is easier than for an imperative language:
- There is less to compile - you only have to support the core relational operators and be able to use the correct calling convention for external functions.
- You need way fewer targets - for a cloud database, you can probably get away with only supporting x86 linux.
- In a push-style engine a pipeline runs only until it either uses up its input batch or fills its output batch. So you can switch between interpreted and compiled code at the batch boundary rather than having to deal with on-stack replacement.
But it's still a lot of work to write an interpreter AND a baseline compiler AND a cranelift/llvm backend AND make sure that they all behave identically. Not a prohibitive amount of work, for sure, but less work is always nice. So the rest of this post is just ideas on how to reduce the amount of work required.
copy and patch
Copy-and-patch reuses the individual operator implementations from an interpreter, replaces all the runtime parameters by extern constants, pre-compiles the code with llvm, (ab)uses the resulting linker relocations to learn where the runtime parameters ended up in the generated code, and finally generates code at runtime by glueing together these pre-compiled chunks and editing the runtime parameters. There's also some fiddling to make the register allocation work out reasonably, which I don't understand yet.
This offers support for all of llvm's targets, the full optimization power of llvm within each operator (except constant propagation of runtime parameters), reasonable register usage between operators, and codegen at close-to-memcopy speeds.
I have some reservations though. First that it depends on the gnarliest, most under-maintained parts of the entire computing stack, and that it's abusing those parts for a totally different purpose than was intended. Second that the lack of inter-operator optimization might be a handicap when operators are small/simple.
The original paper showed impressive results on their wasm implementation, but Titzer's benchmarks above of the same implementation are much less compelling and I haven't investigated the differences in methodology. The author of the original paper is currently working on a lua implementation whose early results are promising, but it's still WIP. The new python jit is using a separate implementation of the same ideas but they are not yet showing meaningful speedups on real programs (although to be fair it's still early days).
I'm keeping an eye on copy-and-patch, but I want to see someone else ship before I invest lots of time in mangling linker scripts.
wasm all the way down
Browsers already poured millions of dollars into wasm backends to solve more or less the same problem. So why don't we just compile our queries into wasm?
The major downside is that this means taking eg V8 as a dependency and having little to no control over its runtime behaviour. With llvm you at least control when you're compiling code, but V8 is going to be jit-compiling stuff in background threads and using unpredictable amounts of resources. But maybe it's possible to rip out just the wasm code and have more control over the jit?
Wasm is also not an ideal compile target, for a variety of reasons:
- Only a limited selection of simd instructions.
- No branch hints (yet) and no control over basic block ordering (eg for cold blocks like failed bounds checks).
- Wasm backends can't make any assumptions about aliasing or shadow stack usage, so you still have to do your own mid-end optimizations.
- With 32bit address spaces you only have 4gb of memory, so you would have to patch V8 to allow virtual memory mapping data in and out of the wasm address space.
- With 64bit address spaces the bounds checks on each memory load/store are expensive, so you would want to patch V8 to disable them.
- The wasm binary encoding prioritizes network bandwidth over cpu cost. Encoding and decoding all those variable-length integers is a waste of time when you're only using wasm as an IR in memory.
As a minor detail, it's not obvious whether or not you would still want your own interpreter. Sure, the wasm backend has a wasm interpreter, but then you have to spend time converting to wasm AND the wasm interpreter has much smaller operators than your query plan, which probably means higher interpreter overhead? Benchmarks needed.
The mutable database project is experimenting with compiling to wasm.
interpreters for free
If you've written a compiler then you can generate an interpreter by just compiling each operator separately and generating some glue code for the dispatch.
The spidermonkey baseline interpreter is generated by the baseline compiler and shares much of the same code. An additional benefit of generating an interpreter is that you can also directly control register usage in the dispatch loop rather than relying on awkward tricks in c.
This doesn't solve the problem of having a separate baseline and optimizing compiler, but maybe those could also share a lot of code? Eg can we do isel at the ir level so that both compilers share the same codegen?
Or is an interpreter and baseline compiler alone enough to be commercially viable? The umbra baseline compiler isn't far off llvm in their published benchmarks - fancy optimizations aren't as necessary when we control the input code.
Inkfuse takes this idea a step further and generates a vectorized interpreter. That makes the interpreter tier much faster, which means they can afford for the next tier up to be a slow optimizing compiler. It seems like this might have some of the downsides of a vectorized interpreter too though, in that you now have to awkwardly break up eg hashtable probes into separate vectorizable operations. But maybe some of the benefits could be had without going all the way to the standard vectorized design?
compilers for free aka wasm all the way up
I'm generally skeptical of meta-tracing systems like truffle and rpython. Too many heuristics and too much unpredictable runtime machinery. But the idea of generating a compiler from an interpreter is still seductive.
Weval is a much simpler system. It works on any interpreter that can be compiled to wasm rather than requiring that you write your interpreter using some special framework. And the partial evaluation is controlled by explicit calls to add context, rather than by runtime tracing and a pile of heuristics.
It's unclear how quickly weval compiles programs or how good the generated code is. But weval is actually shipping which is an improvement on the above ideas.
fin
That's all the things.
If you have a database and you want a baseline compiler, I'd like to write it. Call me :)
If you want more like this, there will be a low-latency compilation track at HYTRADBOI 2025.