Inspired by Ji Yi's homework assignment, I decided to skim all 360-odd papers in the Psychology of Programming Interest Group archives.
Yi reports his students taking ~10 hours to skim 100 papers over a single weekend. His students are clearly way more disciplined than I am. I dragged it out for months. It was brutal.
Towards the end I did finally get up to about 50 papers a day, so if I do this again for other journals I'll probably just take a random sample of 50 papers and try to do the whole lot in one go.
What did I learn?
Not a great deal about the psychology of programming itself. For the most part the field doesn't feel like a stumbling progression towards enlightenment, but just plain stumbling.
Here are some common failure modes that frustrated me:
-
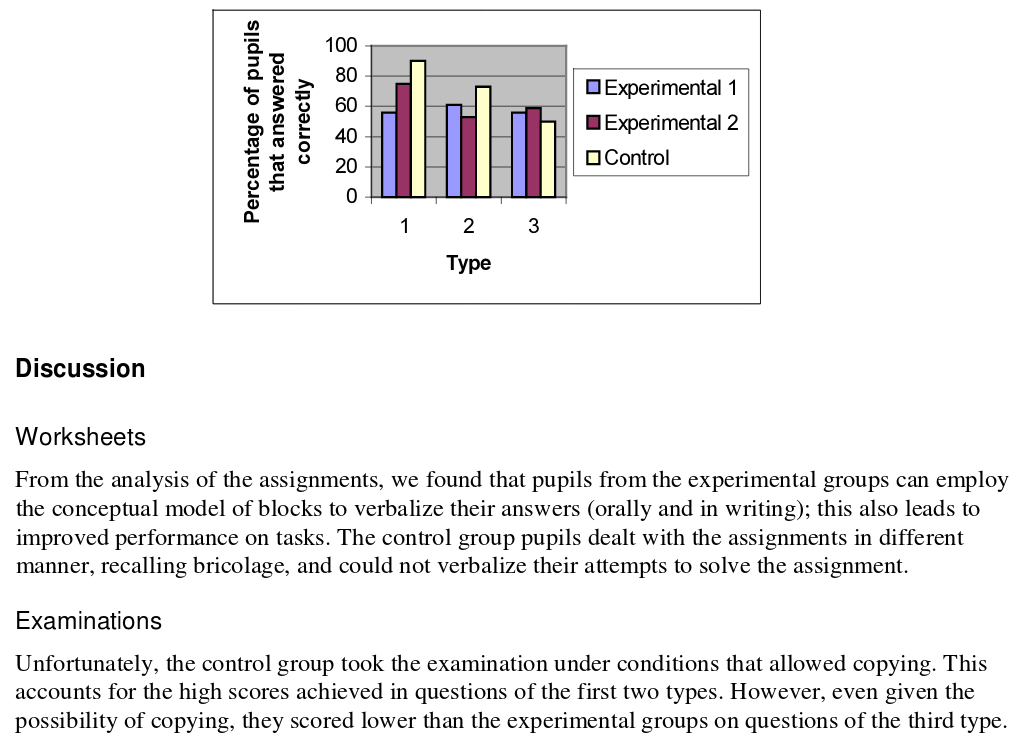
Plain bad science, especially in the early years where a lot of the experiments are 'my pet project vs the world' and somehow the pet project always comes out looking good. My favorite example has a graph where the control group are clearly performing better, and the author explains this away, saying it's because the control group were cheating, and in the conclusion of the paper declares the treatment a success. And it was published!
-
Failing to validate instruments. In particular, a lot of papers that involve coding qualitative data didn't bother to have two people code the data independently to check for agreement.
-
'We have to do some science, and this is science'. Many of the experiments are from the start clearly incapable of answering the original question. I realize that getting good data for these subjects is hard, but the opportunity cost still stings. Do a different experiment!
-
Theoryless science. For example, one paper had programmers read programs under an eye-tracker and found there was a significant difference in the gaze patterns between the more experienced group and the less experienced group. So what? There's no suggestions as to what it means or how it can be used or under what conditions it's expected to be replicable. These papers typically end with "further research is required" and then no further research materializes.
{kind=link}
The last point is often detectable right at the beginning. If I read the description of the experiment and I can't even make up an interesting result, that's not a good sign.
There were also a lot of papers that read like "I found this in a book, we should apply it to programming". I don't know if it's fair to call that a failure mode, but I rarely found anything enlightening in these and most of them were not followed up with papers where they actually apply the idea.
On the positive side:
-
There are a ton of negative results. PPIG seems to be totally willing to publish failed experiments, which is awesome.
-
Things get better over time. Somewhere around the mid-2010s I started finding papers that actually seemed like results. The series of papers on testing whether students form consistent models is a particular highlight - it starts with an interesting correlation, then some failed replications, then refinements of the test, then some successful replications, then more refinements, then combining it with interviews to test validity. It's not sexy, but it does seem to be actual progress towards a reliable measure of one specific leak in the education pipeline.
I have a sort of vague idea that most of this work is just attacking things at too high a level. Programming is a big, diverse, complex skill and we don't really understand really basic subskills yet, or even know how to break it down into subskills. Without that it's impossible to know whether it makes sense to extrapolate any one set of results. If barely trained students benefit from syntax highlighting, does that mean professional programmers will? Or programmers in other languages? Or programmers dealing with programs longer than 50 lines? We have no idea.
Much of this reminds me of Feynman's stories about rat experiments.
...his papers are not referred to, because he didn't discover anything about the rats. In fact, he discovered all the things you have to do to discover something about rats.
What are the things we have to discover before we can discover things about programming? I have no idea.
Anyway, here are the full notes. They're highly opinionated and I made no attempt to be fair to the authors. If I said something mean about your research, don't worry - I barely read it anyway :)
EDIT PPIG broke all their urls :(
1989
1990
Using Systematic Errors to Investigate the Developing Knowledge of Programming Language Learners
Two year programming class. 100 engineers. Errors in semicolon use concentrated on specific contexts, even though students have learned explicit syntax rules. Later errors become uniformly distributed ie attention lapses rather than misunderstanding.
Students don't learn syntax from specification of syntax - need contextualized experience. Parallel to natural language learning.
Opportunistic Planning in the Specification Stage of Design (full paper)
Single engineer observed writing spec in the wild for three weeks. Claimed to be following hierarchical plan but was observed deviating opportunistically.
Tools should allow interrupting planning of one component to jump to another.
Empirical Study of Design in an Object-Oriented Environment
8 experienced programmers - 4 OOP beginners, 4 OOP experienced. Up to one day to solve two problems. Observed heavy resuse of solutions/schemas once discovered.
1991
1992
ACE - An Application Construction Environment
Framework for building end-user programming environments. Aims for progressive specialization where programmers hand-off partially finished environments to end-users. No study on actual users.
Addressing the psychology of programming in programming language design
Judge programming language by breaking writing down into steps, and look at how much knowledge required to choose between options at each step. Novel language, observe four paper writers working through problems. Example of a macro feature where the correct choice is not clear.
Provides a method for evaluating how natural/obvious a given language or feature is.
An analysis of novice programmers learning a second language
Studies transfer of 'plans' learned in Pascal to Ada or Icon. 13 students with Pascal experience. 3 work in Pascal, 5 in Ada, 5 in Icon. Observed, broken into episodes, episodes classified by consensus.
GPT's preparation of students for programming in the real world
Two week industrial course for new graduate hires. Subjects forced to work only in company hours - no last-minute rush - teaches important of planning/scheduling. Role-play vague and unhelpful customer. Uni courses have to be fair => perfect environment - better learning from realistic disruptions.
Possible extensions to the Byrd Box tracer aimed at experts
Proposes study of how expert Prolog programmers use tracer. Didn't actually perform study.
2nd and 3rd year students. 51 returned questionnaire and some were interviewed? Focused on four courses that use formal methods.
Students struggle to manipulate formal expressions by hand. Need automated tools. Only realized relevance of early course much later, when it was too late. Don't believe that formal methods are used 'in the real world'.
Do expert programmers develop better working memory, or do they learn to use external memory more effectively? Notice that experts jump around more often, while beginners tend towards linear program generation.
10 professionals. 12 2nd year undergrads.
Experiment 1. Have to program while speaking strings of digits - strains working memory. Expert performance did not suffer. Novices have more errors under suppression, and jump around code more often.
Experiment 2. Write a program using a program that doesn't allow lines to be edited after hitting enter. Experts produce more errors than novices in this environment.
Suggests that experts don't develop more working memory, but instead switch to strategies that use external memory more.
Some thoughts on designing an intelligent system for discovery programming
Plan for a dynamic visualization of code execution.
Teaching formal software engineering at Loughborough
Incoherent.
Text vs graphics in Prolog tracers
13 subjects solve problems using one of three tracers. No clear differences noted.
The Design and Application of Visually-Oriented Tools for the Use During Software Development
Seems to be research proposal, not a paper.
The interpretation of states: a new foundation for computation?
Proposes a model of computation based on agents which make discrete observations of state?
Visual programming & visualisation of program execution in Prolog
Graphical version of prolog. Slides only.
1993
1994
An Experimental Evaluation of Different Proposals for Teaching Prolog
Two axes. #1 whether common patterns are taught. #2 whether explicit mappings are given between example and exercises. Shipped experiment as free online class. No results yet.
Case study in UK bank. Large team. Interviews and questionnaire. Early results only. Nothing notable.
Computer Programming for Noughts and Crosses: New Frontiers
Agent-based model of programming for OXO games. No experimental results.
Self-paced LISP course. 25 students, no programming experience. Taped sessions and students think aloud. Analyses student explanations.
Better-performing students made more complex and more connected explanations of LISP concepts, and asked more questions of other students. No data or statistics given.
Moilère: A Visual Programming Environment Based on a Theatre Metaphor
Visual OOP env built on smalltalk. Based around theatre metaphor. Abstract only.
Towards an Experiential Description of Programming and Learning to Program
14 students x 6 interviews. Self-reported experience of programming. No results.
1995
Studies of visual programming useless because they focus on toy problems. Personal model of how OOP programming works.
Questionnaire to explore connection between programming ability and math ability. No results.
An investigation into strategies employed in solving a programming task using Prolog
32 2nd year undergrads. Experience with procedural programming. Asked to solve problem in Prolog.
Two different strategies observed. Both were procedural.
Comparing program comprehension in different cultures and different representations
R-technology - visual control flow developed in Soviet Union. 24 professional R-tech programmers. Comprehension test for two 150loc programs. Then asked to write a program in either C or R-tech.
No results.
Control strategies used by expert program designers
Wrong link.
Case library tool for existing courseware design suite. Designed by observing users on mockups. Tool was not effective.
Do diagrams make us smart(ER)?
Study how multiple representations of logic helps. No body.
Documentation skills in novice and expert programmers: an empirical comparison
20 novice students. 7 faculty members. Add comments to ADA program.
Falsified hypothesis that experts would produce semantic comments and beginners would produce paraphrases of code.
Graphical version of LISP supporting execution of partial programs. No body.
Forms/3, a declarative graphical language
No body.
Knowledge exploration in design: communicating across boundaries
Case studies of multi-disciplinary design problems. Unclear results.
Learning graphical programming: an evaluation of KidSim
Kids programming environment. 56 children, 10-13yo. Varied problems, class schedule and instruction.
Clear enjoyment, but no good evidence of transferable learning.
MADLab: masking and multiple bug diagnosis
Toolkit for studying debugging of programs with multiple bugs. Little information.
14 grad students. Experienced in structured programming, 6 months experience with OO. Procedural and OO program with identical spec. Asked to make changes.
Worse performance on 4/6 tasks for the OO group.
Mental representation and computer use
No body.
Prolog without tears: an evaluation of the effectiveness of a non Byrd Box model for students
New Prolog tracer based on different mental model of evaluation. 48 cogsci students. Given printed program, worked through modified versions in one of three tracers and asked to identify differences.
Exposure to language predicts success more than exposure to tracer tool. Students were more successful with Plater tracer.
Dev environment based on observing what programmers actually do, rather than what models prescribe.
No body.
The evaluation of TED, a techniques editor for Prolog programming
32 students. 10 week course. Standardized teaching methodology. Group 1 got standard course. Group 2 got standard course with different method of teaching recursion. Group 3 got same course as 2 but also used the TED editor.
Group 3 made less mistakes overall. Mixed results for different problems. TED editor not described.
Transforming verbal descriptions into mathematical formulas in spreadsheet calculation
Argues that this process goes through an intermediate imagery step.
No body.
Using episodic knowledge in design
No body.
Validating knowledge based systems with software visualization technology
No body.
1996
1997
1998
Sarcastic faux history.
Software reuse from an external memory: the cognitve issues of support tools
Examines process of finding software to reuse. No data.
1999
Skipping the doctoral consortium - no bodies.
The need for computer scientists to receive training on people skills
Two environments experienced by the authors where people skills were lacking.
Spatial measures of software complexity
Proposes metrics on callable-from graph. No evaluation.
Representation and structure in the re-use of design rationale by novice analysts
18 1st year undergrads. Graphical vs tabular vs narrative representation of design rationale. Options-based vs criteria-based (unclear on meaning).
Narrative format had slower response times, fewer correct answers. Graphical and tabular were matched. Criteria-based had similar times to option-based but more correct answers.
Programming with a purpose: Hank, gardening and schema theory
Visual language for cognitive modeling. Focus is not on building models but on understanding them. Used for student project. Questionnaire at end of course, qualitative analysis.
Students liked having no textual syntax. Found it easier to understand Hank models than Prolog models. Able to understand each others programs. Could understand execution process. Hank was useable with pen and paper.
Mental representation and imagery in program comprehension
32 c programmers. 32 spreadsheet programmers. Checking whether programmers build mental models based on control flow or data flow. Used recognition task with priming to see whether recognition is improved by primes nearby in control flow or nearby in data flow. Not clear what language the test program was in or how distance is judged in each model.
Interpretation of results is not clear to me.
Investment of attention as an analytic approach to cognitive dimensions
Considering user action in terms of choosing where to invest limited resource of attention eg spend attention looking up api call vs just hope that memory is correct.
Getting a GRiP on the comprehension of data-flow visual programming languages
Investigating visual programming languages for novices.
No body.
Program comprehension in Prolog. 10 experts, 10 novices, 10 non-programmers. Asked to read program, reconstruct from memory and then explain purpose. Programs are very short.
Considered 4 different ways of choosing key points of program. Only way for which difference in recall was significant was 'schemas' - common patterns of computation in prolog eg build list and then aggregate.
Describing future studies proposed for Hank. No results yet.
EPSRC and support for the psychology of programming
Something about funding decisions.
ENCAL: a prototype computer-based learning environment for teaching calculator representations
Piaget-ian construction of mental imagery. Traditional calculators and algebra notation don't provide mapping to any concrete imagery, so children struggle to map classroom math to their own experiences. Proposes a computer environment with multiple representations, at different levels of abstraction, running simultaneously.
Desirable features of educational theorem provers - a cognitive dimensions viewpoint
Questionnaire on usability of theorem provers. Subjects complained about vague and sometimes inapplicable questions.
Computer science undergraduates learning logic using a proof editor: work in progress
170 1st year students in logic course. Post-course questionnaire.
Students preferred to memorize rules rather than practice with Jape. No other results yet.
10 science teachers. Five problems in Word, where knowledge of underlying implementation would allow easy solution.
Most subjects resorted to trial and error, and out-loud gave incorrect explanations of underlying mechanics. No attempts to falsify their models.
Proposes that experiments in programming would produce similar results.
2000
Uncovering effects of programming paradigms: Errors in two spreadsheet systems
Want to see if changing naming scheme in spreadsheets from individual cells to named blocks of cells changes the kinds of errors that users make. 154 1st year undergrads, various subjects. Four different spreadsheet tasks, given in various orders. Compared Excel vs Basset (home-grown system). Errors are categorised by author.
Lower number of errors for some tasks, higher for others. No clear numbers for categories.
Tools for observing study behaviour
Tool for recording student interactions with a Smalltalk environment.
The influence of the psychology of programming on a language design: Project status report
Developed a language based on review of past psychology of programming results. Experimented with different forumulations of boolean queries. Found confusion over 'AND', precedence/grouping and users totally ignoring parens.
The effect of programming language on error rates of novice programmers
GRAIL vs LOGO. 26 1st year undergrads, no experience. Similar exercises for both groups, but not identical.
Fewer errors for GRAIL. Difference larger for syntax errors than for logic errors. Presumably graded by author.
Some problems of programming in robotics
Theorising about how to teach robotics to children.
Programmer education in Arts and Humanities course degree
Questionnaire given to 14 students. Self-reported background / computer use. Programming quiz.
Structured interview given to ? students assessing learning style, development process.
Concludes that sample is too small to say anything of interest.
On the use of functional and interactional approaches for the analysis of technical review meetings
Transcribed 7 design meetings. Cut up into speech acts, classified according to coding scheme developed during analysis. Classifies into 5 kinds of exchanges, using unclear methodology.
How do people check polymorphic types?
Questions: 34 what is the type of this, 34 why is this an error. 6 subjects, all of whom at least post-grad. Video categorised by the methods subjects used to answer, unclear methodology.
How a visualization tool can be used: Evaluating a tool in a research & development project
Jeliot - animations for understanding algorithms.
Programming intro w/ 564 undergrads, didn't regularly use Jeliot. Short programming course w/ 37 high school students, course based around Jeliot. Semi-structured interviews for small numbers of students in each group, not explained how they were selected.
Rejected by group 1 lecturer because of library issues. Students found UI confusing.
Gotos Considered Harmful and Other Programmers' Taboos
Discusses how taboos spread socially. Argues that all the notable taboos are about crossing abstraction boundaries.
Expertise and the comprehension of object-oriented programs
16 novices. 16 experts. Showed a program for 2 or 10 seconds. Asked 5 comprehension questions. Experts perform better in both 2s and 10s cases. Data- and control- flow questions benefit from 10s more than function, operation and state questions.
Experiences with novices: The importance of graphical representations in supporting mental mode
Trying to teach beginners the mental representation of recursion used by experts.
49 students taught to use a diagrammatic representation of recursive programs. Test mental model by giving a list of possible solutions and asking which ones work correctly. Students who were tested with diagrams made fewer errors than students who tested with diagrams ie model was learned but failed to transfer to normal code.
Cognitive Dimensions: An experience report
Design of real-time temporal logic language using cognitive dimensions.
Cognitive Dimensions of Use Cases: Feedback from a student questionnaire
Questionnaire on UML use cases, covering cognitive dimensions. 14 students.
An assessment of visual representations for the 'flow of control'
Testing whether to use arrows, lines or juxtaposition for control flow. 84 students. Given maze in each style and have to follow paths. Measured response time. Arrows were fastest and most accurate.
A framework for knowledge: Analysing high school students' understanding of data modelling
How well are mental representations transmitted to students via verbal discussions? 3x groups of 7-9 high school students, oral interview + written questionnaire, questions on syllabus material.
High school students suck at definitions.
Questionnaire sent to users and designers of a prover assistant. Answers on numerical scale. Minor differences in responses between the two groups.
A Cognitive Dimensions questionnaire optimised for users
Generalised CD questionnaire. Tested on users of various systems. Not clear whether this is useful.
2001
Using a Graphical Design Tool for Formal Specification
Adapt UML for formal specs. No evaluation.
The Usability of Formal Specification Representations
51 students, 4 questions, each a choice of two implementations of simple problem. After four weeks of Z classes, given same set of questions described in Z.
Claims strong shift in approach, but just eyeballing the numbers doesn't look like much.
The Science of Web-Programming
Functional programming in templates. Maybe misunderstood, but seems incredibly trivial.
The Model Matters: Constructing and Reasoning with Heterarchical Structural Models
Compares 4 formal modeling methods. Evaluated directly by authors on a single example. Prefer tables over trees.
The Coach - Supporting students in the area of error reports
Smalltalk env. Made a 'coach' with list of recent actions and error messages. No evaluation yet.
The Application of reflective Practitioner to Software Engineering
Advocates for using this practice. Not totally clear on process or goal, but seems related to the problem of not begin able to teach implicit knowledge.
Team Performance Factors in Distributed Collaborative Software Development
Comparing two teams of students, high vs low performance. Coded email and irc histories.
Concludes that communication is important.
Experiments with graphical languages.
Different graphical layouts for programs. 21 students tested on comprehension of graphical vs textual. 60 students tested on comprehension of different graphical layouts. No main effect in either.
Additional cognitive skills test, no correlation with main experiment.
Switching between RLT and LTR writing in Word is confusing. Gave students an explicit conceptual model.
Control group exam was under different conditions. Used to explain their better performance.
Research Agenda for Computer Science Education
Argues for more empirical research in CSE.
Patterns in working hours for remote learners in an OU course.
Native-End User Languages: A Design Framework
Plans for end-user programming in languages other than English.
Long Term Comprehension of Software Systems: A Methodology for Study
there is little in a way of a conclusion, other than the common oft repeated call of, ‘we need to do more research in this area
Human and "human-like" type explanations
Comparing human approach to explaining type errors to approach of authors' new type-checker. Coded by author, without explanation.
Gave (translation of) general CD questionnaire to 10 spreadsheet users.
Evaluating a new programming language
CD questionnaire to evaluate new language, given to 5 professional programmers.
Designing a Programming Language for Home Automation
Media Cubes. Physical cubes that correspond to (dataflow?) operators. Placed together to create program. Provides direct referencing eg place cube on tv to reference tv.
Iota.HAN. ML / Pi-calc based language.
Cognitive Dimensions Profiles: A Cautionary Tale
Ignoring some cognitive dimensions in analysis can lead to missing effects on those dimensions.
An Open-Source Analysis Schema for Identifying Software Comprehension Processes
Protocol for analyzing spoken transcripts to determine whether programmers are understanding a given program by comparing against preexisting domain knowledge or by recognizing patterns of code.
A Study of Human Solutions in eXtreme Programming
Mostly XP advocacy. Little in the way of actual numbers.
Planned data collection from student projects.
Studying language high-school students use.
2002
Shared Data or Message-Passing - A Human Factor in Technical Choices?
How do people choose between the two? Give parallel programming problems to students along with Myers-Brigg test.
Hugely forking paths. Only 0-3 students per MBTI / shared-mv-messaging intersection.
Trying to define programming in light of rising end-users.
Ideas on difficulties - loss of direct manipulation, use of notation, abstraction.
Visualizing Roles of Variables to Novice Programmers
Break variables into different types - constant, counter, control etc. Apply different graphics when visualizing program.
No evaluation.
The Roles Beacons Play in Comprehension for Novice and Expert Programmers
45 students. Given single line, judge how likely it is to have come from a binary search. Ratings(?) influenced by expertise.
30 students. Given single line, map it to one of three algorithms. Unclear results.
19 students. Shown algorithm and asked to comprehend/memorize (under eyetracker). Then given comprehension test. Divide sections of code into categories, normalize time in each category by screen area. Experienced group focused more on 'complex' category.
The Misplaced Comma: Programmers' Tales and Traditions
Speculation on programmer folklore.
Softening the Complexity of Intelligent Systems Programming
Students struggle surprisingly with symbolic systems. May be caused by overhead of manipulating data-structures. Suggest pattern-matching support in language to help.
Revitalising Old Thoughts: Class diagrams in Light of the Early Wittgenstein
...
Programming Aptitude Testing as a Prediction of Learning to Program
33 students. No significant correlation between VB course final exam grade and high-school grades or SAT grades. Huoman programming aptitude test explains 25% of final grade.
Patterns for HCI and Cognitive Dimensions: Two Halves of the Same Story?
HCI researcher compares pattern languages to cognitive dimensions.
On Concurrency in Educational Software Authoring Systems
Educators given animations of systems and asked to describe how they work.
No coding or statistical analysis.
Inexperienced subjects tended to describe each entity until influenced by external event. Suggests describing systems in terms of individual behaviors and cross-entity conditions for behavior change.
Modelling Software Organisations
Proposes agent-based modeling of software organizations.
Making the Analogy: Alternative Delivery Techniques for First Year Programming Courses
Anecdotal reports from lecturer of first-year programming course.
3 main problems. Students have no prior exposure to computational thinking, or even basic logic. No familiar experience to compare most programming concepts to. Unused to rigid syntax rules.
Suggests several analogies for use in teaching.
Learning Styles in Distance Education Students Learning to Program
Distance learning students. Given questionnaire to assess learning style.
Many forks. Significant gender differences.
HASTI: A Lightweight Framework for Cognitive Reengineering Analysis
Presents simple computational model of human cognition. Suggests studying software tools in terms of how their use maps onto this model.
Evaluating Languages and Environments for Novice Programmers
Common-sense ideas for comparing languages and IDEs.
Dimension Driven Re-Design - Applying Systematic Dimensional Analysis
Unclear. Map language spec into this tool and automatically compute CDs?
Class Libraries: A Challenge for Programming Usability Research
Library design should be treated as a usability problem.
A Study of Usability of Z Formalism Based on Cognitive Dimensions
CD questionnaire given to students in Z course reveals many issues, too many to list here.
A Comparison of Empirical Study and Cognitive Dimensions Analysis in the Evaluation of UML Diagrams
Two different notations for UML diagrams. CD analysis favours one. Multiple-choice exam given to students shows no significant difference.
2003
A development study of cogntive problems in learning to program
Anecdotal reports from programming course.
Students can often give the correct code without understanding how it works. Often mislearn concepts, while making the correct noises.
Very similar to previous paper.
Applying Cognitive load theory to computer science education
Ideas for how to reduce cognitive load when teaching programming.
Characterising software comprehension for programmers in practice
Empirical studies of programmers tend to take place in very artificial settings. Plans to study programmers in-situ.
Cognitive Dimensions of tangible programming techniques
At lexical level TUIs provide no advantage - too small a vocabulary, no established conventional symbols, no significant improvement in interaction speed or recall.
At syntactic level - more possible kinds of relationships (position, orientation, proximity...), input-only interface (eg no undo).
Cognitive Dimensions questionnaire applied to visual languages evaluation - a case study
CD questionnaire given to 2(!) subjects. Both were critical of the questionnaire.
Does the empirical evidence support visualisation?
Brief survey finds mixed support for visualization in programming tools.
First results of an experiment on using roles of variables in teaching
Categorize variables into one of 10 roles.
Taught 80 students with a) normal methods b) variable roles c) variable roles + animated simulator which shows roles.
Conclusion is confusing - raw data looks to me like roles group did worse in their final exam, but author claims that poor grading was the cause.
Investigating the influence of structure of user performance with UML interaction diagrams
Tries again with the two different UML notation. Three different studies show no difference in performance.
Java Debugging strategies in multi-representational environments
Java debugger with ghetto eye-tracking. 49 novice students. Given spec and test cases, then given 10 mins in debugger to fix program.
Numbers are in a different paper. This one only discusses verbalizations from 2 subjects.
Subjects started by reading code almost top-to-bottom. Debugging switched between forward and backward reasoning.
Little Languages for Little Robots
Teaching language design by working with students to build a language for programming Mindstorms robots.
Software Effort Estimation: unstructured group discussion as a method to reduce individual biasis
Groups of programmers produce less over-optimistic estimates than individual programmers (effect size 1.25).
Seems similar to proposed mechanism in Superforecasters - if estimate is ideal time + list of things-that-might-go-wrong, then compiling things-that-might-go-wrong from whole group should provide better coverage.
Some parallels between empirical software engineering and research in human computer interaction
Current experiments in psych-prog do not inform practice. HCI faced similar criticism in previous decades and changed focus from lab experiments to field studies.
Team coordination through externalised mental imagery
Several observed cases of mental imagery originating in one dev and spreading throughout an entire team.
Tensions in the adoption and evolution of software quality management systems
4 companies. (4?) quality managers. Semi-structured interviews on department structure, history, responsibilities, practices.
Not clear what the conclusions are.
Towards authentic measures of program comprehension
Scheme for grading student explanations of programs.
Using cognitive dimensions to compare prototyping techniques
CD analysis suggests that existing categorization of prototyping tools into lo- and hi-fidelity is not enough.
Identifies 4 key activities: authoring, validation, implementation, confirmation. Not clear how these relate to categorization.
Using laddering and on-line self-report to elicit design rationale for software
Design rationale may not be available as explicit, conscious, verbalizable knowledge.
Authors elicit rationale from students designing web pages using real-time self-reporting and laddering. (Laddering seems similar to root-cause analysis, but for exploring knowledge rather than causes).
Using the cognitive dimensions framework to measure the usability of a class library
Suggests a variant CD specifically designed for evaluating libraries.
2004
Roles of variables and strategic programming knowledge
Variable roles again. No new results.
Programming without code: a work in-progress paper
Proposal for natural language programming for kids.
Extreme programming: all of the elegance but none of the models?
Plans for studying extreme programming.
XP: Taking the psychology of programming to the eXtreme
Review of previous XP studies.
Same as previous paper, but with a real eye-tracker this time. Similar results.
Collaborative IDE for teaching. Anonymous group work was popular.
Towards the development of a cognitive model of programming: a software engineering proposal
Proposes teaching system that tracks students weaknesses down to the level of individual concepts. (Not unlike Khan academy).
Bluetooth network simulation for teaching. No evaluation.
Many examples of metaphorical language used by devs.
Learning object-oriented programming
Anecdotal observation of students. Students were reluctant to draw object diagrams before coding. Instructor didn't approve of their modelling choices.
Learning and using formal language
36 psych students, later 64 vaguely-sourced adults. Tested on 'does regex match string' and 'make a regex to match this class'. Exposure to former doesn't improve performance in latter (but only 6 questions per person?).
Collected program snippets from Java mailing lists (mostly from bug reports and patches). Don't really follow the results.
Factors affecting course outcomes in introductory programming
75 students. Computer Programming Self-Efficacy Scale questionnaire. Program comprehension test. Program recall test. Weak correlations between self-efficacy at end of course and test scores.
Evaluating algorithm animation for concurrent systems: a comprehension-based approach
Proposes evaluating understanding of concurrent systems with a particular talk-aloud protocol and coding system.
Dynamic rich-data capture and analysis of debugging processes
Proposes using restricted focus viewer and other recording methods.
Design diagrams for multi-agent systems
Proposes an extension of UML to handle multiple agents.
CORBAview: a visualisation tool to aid in the understanding of CORBA-based distributed applications
Visualisation tool for CORBA. Records events, allows replay. No evaluation.
Comparison of three eye tracking devices in psychology of programming research
3 commercial eye-trackers. 12 subjects given program comprehension tests. Head-mounted device took longer to setup and was less accurate but allowed subjects to move around.
Aspects of cognitive style and programming
~150 students. Modified Witkin field-dependency test. Digit span test for working memory. Correlation to exam results 0.1-0.2 for working memory, 0.2-0.4 for field-independency.
(Would effect of field-independency be explained away by spatial IQ?)
An Inter-Rater Reliability Analysis of Good's Program Summary Analysis Scheme
Coding scheme for program summaries shows ~80% agreement between 3 users. Suggests refinements to the scheme to reduce differences.
An Examination of E-Commerce Homepage Design Guidelines by Measuring Eye Movements
11 subjects visit ecommerce pagers under eye-tracker. Self-reported data agreed with eye-tracker - users look at top-left or top-middle first.
A first look at novice compilation behavior using BlueJ
63 students. Record full source code every time they hit compile. More than half of errors accounted for by missing semicolons, misspelled variables, missing brackets, illegal start of expression, misspelled class. Majority of recompiles after error take place within 20s. Vast majority of recompiles after success take place after > 5 minutes.
2005
A Framework for Evaluating Qualitative Research Methods in Computer Programming Education
'Grounded Theory'. Framework for guiding qualitative research.
Attitudes Toward Computers, the Introductory Course and Recruiting New Majors: Preliminary Results
Computer literacy course. Computer Attitude Scale questionnaire. Attitudes became increasingly negative over the duration of the course.
Attuning: A Social and Technical Study of Artist-Programmer Collaborations
Interviews with 4 programmers and 2 artists. Conclusions unclear.
Concretising Computational Abstractions: What works, what doesn't, and what is lost
ToonTalk. No body.
Effects of Experience on Gaze Behavior during Program Animation
18 high-school students in undergrad programming course. Animate three short programs. Comprehension task. Gaze-tracking.
No significant variation in behaviour wrt experience.
Factors Affecting the Perceived Effectiveness of Pair Programming in Higher Education
58 students pair-programming. Observation, questionnaires, semi-structure interviews, field notes.
Differences in skill level affect collaboration. Debugging tasks reported as particularly tiring / unenjoyable.
Graphical Visualisations and Debugging: A Detailed Process Analysis
29 undergrads. 1 modification task, 1 comprehension task, 6 debugging tasks.
Forking paths. Questionable interpretations of results.
Introducing #Dasher, A Continuous Gesture IDE
Language model for writing C# with Dasher. No evaluation.
Mining Qualitative Behavioral Data from Quantitative Data: A Case Study from the Gender HCI Project
27 male and 24 female subjects. Self-efficacy questionnaire. Spreadsheet with extensions for testing. 2 spreadsheets with bugs.
Female subjects had lower self-efficacy about debugging ability. Less likely to use new debugging features, although no difference in learning time. Introduced more new bugs, but also correlates highly with use of new debugging features.
Pair Programming: When and Why it Works
Ethnographic study of pair programming at two companies. No results yet.
PP2SS - From the Psychology of Programming to Social Software
No body.
Preliminary Study to Empirically Investigate the Comprehensibility of Requirements Specifications
Pilot to study whether Java implementation of Irish electoral system is easier to understand than the legal language.
8 software eng postgrads. Comprehension questionnaire. Java group scored worse and expressed more confusion and frustration in talk-aloud.
Psychometric Assessment of Computing Undergraduates
Aptitude Profile Test Series (sounds like an IQ test) administered to 34 students. Correlates 0.4 with exam results.
Demographic survey of 197 students. Country of birth and first language significantly affecte exam results - non-english students fare worse.
APTS and demographic survey of 80 students. Students with prior experience in programming fared better. APTS correlates 0.3-0.4 with exam results.
Notes sample bias - students that volunteered are much more motivated than those that didn't.
Rating Expertise in Collaborative Software Development
45 pair programmers asked to rate ability and experience for themselves and for peers. Unclear results.
Representation-Oriented Software Development: A Cognitive Approach to Software Engineering
Deja vu. Published effectively the same paper a few years earlier.
Roles of Variables in Experts' Programming Knowledge
13 professional programmers asked to sort variables into groups based on similarity. Claims that grouping agrees with roles, but not clearly falsifiable.
Short-Term Effects of Graphical versus Textual Visualisation of Variables on Program Perception
12 students. Field-dependency test. Taught variable roles. Visualisation of pascal program, asked to write program summaries. Questionnaire about tools.
Unconvincing analysis.
Sidebrain: A Sidekick for the Programmer's Brain
Tool that records stack of open tasks, notes and queue of pending tasks.
(Particularly interesting, because I made a similar tool for myself but didn't use it for very long.)
No evaluation.
Software Authoring as Design Conversation
Talk-aloud of subjects working on sheep-dog game. No real results yet.
Proposes framework for studying social dynamics in teams.
The Influence of Motivation and Comfort-Level on Learning to Program
57 students. Motivated Strategies For Learning Questionnaire. Modified version of Rosenberg Self-esteem questionnaire. Modified version of Computer Programming Self-Efficacy Scale.
Samples test scores were representative of whole class.
Intrinsic motivation and self-efficacy both correlated with performance at ~0.5.
The Programming Language as a Musical Instrument
Argues that live coding is an interesting topic for PPIG.
The Psychology of Invention in Computer Science
Mines existing published interviews with famous computer scientists for quotes on creativity.
The Role of Source Code within Program Summaries describing Maintenance Activities
Studying code excerpts from Java mailing lists. Couldn't reject the null hypothesis. Not sure I understand the null hypothesis anyway.
Theoretical Considerations on Navigating Codespace with Spatial Cognition
Plans to study whether mental models of code build on existing spatial navigation strategies.
Using Roles of Variables in Teaching: Effects on Program Construction
20 students. Group 1 taught traditionally. Group 2 taught using roles. Group 3 taught using roles and animator. Only group 3 had any students who successfully completed programming task.
2006
Cognitive Perspectives on the Role of Naming in Computer Programs
Unsurprising observations on names.
Comparing API Design Choices with Usability Studies: A Case Study and Future Directions
Plans to study general principles of api design rather than just specific apis.
2 programmers talk-aloud at work. Try to generalize from this a model of how programmers look for information.
Initial Experiences of Using Grounded Theory Research in Computer Programming Education
Still talking about grounded theory without yet reporting any results.
Metaphors we Program By: Space, Action and Society in Java
Studying spatial and social metaphors in javadocs. Don't see any actual examples, just graphs.
Program Visualization: Comparing Eye-Tracking Patterns with Comprehension Summaries
Does gaze predict comprehension? Highly forking, no strong signal.
Reading as an Ordinary and Available Skill in Computer Programming
Ethnographic studies at software company. I don't really know how to summarize this, but it was interesting.
Stories from the Mobile Workplace: An Emerging Narrative Ethnography
Ethnographic study. No real information.
Subsetability as a New Cognitive Dimension?
Studying programming environments by the extent to which one can make useful programs without leaving various subsets of features.
Demonstrates that eg hello world in C or Java involves a large subset of the language features.
Arrange feature subsets as a lattice and examine what can be done in each subset.
Teaching Programming: Going beyond "Objects First"
Object-first teaching leads to students who can't code for-loops. Proposes variable-first teaching - start with teaching variable roles and control flow.
Previous study noted that consistency of mental model in early tests was predictive of long-term success in programming courses. Criticized for being too vague to replicate. Introduces a new marking scheme that doesn't require marker judgment.
The Development Designer Perspective
15 devs and product managers interviewed on design decision process. Little input from professional designers during process. Main factor in decisions was consistency with existing design.
The Effect of Using Problem-Solving Tutors on the Self-Confidence of Students
Tutor program combines explanation with multiple-choice tests. Improvement in test results after use was significant but effect size is small.
Threshold for the Introduction of Programming: Providing Learners with a Simple Computer Model
Somewhat unclear. Talks about 'threhold concepts' - concepts that once learnt change the way the student views computing. Then presents a simplified model of a computer.
Proposes vocab for discussing scm in terms of Vygotskyian model. I don't actually see any vocab though.
Users' participation to the design process in a Free Open Source Software online community
Studies Python Enhancement Proposals. Interviewed 10 active python community members. No obvious conclusions.
Why Don't They Do What We Want Them to Do
Interviewed (all 60?) students. Asked why they didn't use state diagrams for their concurrent systems homework.
Students who used state diagrams did better on their homework.
Widespread reports that state diagrams take too much effort.
Collaboration in mature XP teams
Ethnographic study of XP team. Nothing surprising.
Open source software communities: current issues
Argues OSS communities need to be studied more.
XP and Pair Programming practices
Survey of existing work on XP and pairing.
Agile Stories: Agile Systems and Narrative Research
Anecdote about a programmer with poor communication skills.
A gentle overview of software visualisation
Does what it says on the tin.
Interviewed team leaders of 6 person locator websites. None looked for existing sites or teams before starting. All resisted aggregators combining their content.
An Experiment on the Effects of Program Code Highlighting on Visual Search for Local Patterns
21 students. Asked to find various program fragments. Two syntax highlighting schemes had no significant effect vs black-on-white control.
Abstraction levels in editing programs
Comparing structured editing to text editing. No results yet.
A Competence Model for Object-Interaction in Introductory Programming
Proposes hierarchy of understanding for OOP execution model. 125 students given questionnaire followed by test. Results appear to agree with hierarchy, but some questionable change to data before analysis.
2007
Usability Assessment of a UML-based Formal Modelling Method
Model that combines UML and B. Compared to B alone. 41 students assigned comprehension and modification tasks. UML-B scored higher.
10 students given CD questionnaire on UML-B.
The Learning of Recursive Algorithms from a Psychogenetic Perspective
Give students recursive definition of a language, ask them various questions about it and then ask them to write various recursive functions on the language.
Talks up the benefits of this approach but it's not clear to me from a quick reading what the difference is.
Student Attitude Towards Automatic and Manual Exercise and Evaluation Systems
Survey given to 455 students with 23% reply rate. Students trust automated systems more. Worried that human contact would be reduced.
SQ Minus EQ can Predict Programming Aptitude
19 students given Autism Research Centres EQ and SQ tests. Both correlate with programming test (.44, -.45, p~=.05), combined score correlates more (.67, p=.002). (Combined score also known to correlate with autism spectrum).
Suggested explanation is that high SQ-EQ makes students more likely to rack up hours messing with computers.
Spatial Ability and Learning to Program
49 students in MSc IT. Mental rotation test correlates with success at 0.48. Acknowledges that students with high spatial ability are known to be more likely to pick engineering courses.
Problem Solving in Programming
Argues that students struggly in programming because they lack basic problem solving skills ala Polya. Propses tool that nudges students through the basic process eg making them list what data is known and what unknowns need to be solved.
Moods and Programmers' Performance
Make 72 programmers watch short video clips before debugging test. Small effect on arousal axis, but poor power.
Introducing Learning into Automatic Program Comprehension
Use machine learning for understanding programs. Example of extracting variable roles. Not clear what the learning algorithm is or how it's applied.
From Procedures to Objects: What Have We (Not) Done?
Procedural to OO has been a big shift for teaching. Can't assume that psych results will carry over.
Some of the that is claims are totally unstudied seem to have been published in previous PPIG papers.
Expert strategies for dealing with complex and intractable problems
In-field observation and interviews of 10 programmers working on large complex problems. No body.
Example of Using Narratives in Teaching Programming: Roles of Variables
Anecdotal observations of teaching kids to program using narratives and variable roles - placing kids in the role of a particular variable and playing out live.
Advocates for process of explicitly stating models and (manually or automatically) looking for contradictions in reality to refine the model.
Main example is software tool for expressing explicit models of how software operates. User maps model to code. Tool shows where system violates their model eg calls between two components that don't have a dependency in the model.
Assisting Concept Location in Software Comprehension
Code search that is aware of documentation? Too much jargon, no idea what the tool actually does.
Eye-tracking data is hard to analyze. Complex tasks, difficult to map into simple components for hypothesis testing.
Broke previous data into small chunks and looked at trends over time and switching patterns between activities.
An Experiment on the Effects of Engagement and Representation in Program Animation Perception
PlanAni again. 24 students. Two tests under eye-tracking - 1) predict variable values 2) choose inputs to produce particular values.
Various numbers produced but no idea what they were actually trying to find out.
An Experiential Report on the Limitations of Experimentation as a Means of Empirical Investigation
Failed experiment. Subject sampling/participation messed up by other commitments. Much of the data is missing because subjects didn't get around to writing it down. Two groups behaved so differently in collaborative stage as to be effectively different experiments.
A Roles-Based Approach to Variable-Oriented Programming
Proposes language design to focus on variable roles.
A multidimensional framework for analysing collaborative design: emergence and balance of roles
No body.
Attempting to use GT initially failed. Transcription of recording was impractical so directly annotated the video. Overwhelmed by possible choice of features because they had no actual goal.
Suggests choosing feature categories before starting coding, using structured names for concepts, making a UML model for results, pair coding.
A Categorization of Novice Programmers: A Cluster Analysis Study
Want to be able to group students by current skill level for better targeted teaching.
Give a test to 254 students that follows Blooms Taxonomy. Cluster students by results - observed non-linear skill progression.
2008
XP Team Psychology - An Inside View
Anecdotal report from team of PhD students using XP.
What Happens During Pair Programming
GT concepts for pair programming.
Using Mapping Studies in Software Engineering
Several examples of mapping studies. Notes that coverage is low, both in the mapping studies themselves and in the areas they address.
Towards a Computer Interaction-Based Mood Measure Instrument
Trying to determine mood from mouse and keyboard logs. Analysis is awful.
OOPy folks argue that thinking in terms of objects is innate. Relates various psych findings that don't seem to actually be related to OOP objects. Confusion over the word.
The Stores Model of Code Cognition
Models code cognition in terms of various memory types.
The Importance of Cognitive and Usability Elements in Designing Software Visualization Tools
Designing software with multiple views. Not strongly justified.
The Abstract is an Enemy: Alternative Perspectives to Computational Thinking
Reality is messy, has to be abstracted away to fit in tidy computers. What could go wrong?
Not very convincing examples.
Structured Text Modification Using Guided Inference
Tools that infers regexes from positive/negative examples. Evaluation with 6 subjects vs manual editing with Word and vs manual rename with Adobe Bridge. Large effect size.
Scientists and Software Engineers: A Tale of Two Cultures
Culture clashes between devs and scientists, especially in waterfall style dev.
Observing Open Source Programmers' Information Seeking
More mailing list data-mining. Conclusions are banal.
MBTI Personality Type and Student Code Comprehension Skill
74 students take MBTI test and code comprehension test. Introversion slightly predicts success.
Intuition in Software Development Revisited
Philosophizing.
Integrating Extreme Programming and User-Centered Design
Largely seems to be about integrating mock-ups and end-user testing into XP workflow.
An MCL Algorithm Based Technique for Comprehending Spreadsheets
Using Markov Clustering to try to retrieve logical cell blocks. Minimal evaluation.
A Study of Visualization in Introductory Programming
LOGO clone. Slight improvement in course participation in same year.
Suggests that loops are hard because there is not a 1-1 mapping between text and execution.
A Longitudinal Study of Depth of Inheritance and its Effects on Programmer Maintenance Effort
Data-mining Eclipse repo. Inheritance depth did not predict refactorings.
Testing out systematic lit review with 1 student. Seems to work.
A Comparison Between Student and Professional Pair Programmers
10 students and 6 professionals recorded pair programming. Significant differences in their behavior mean that past studies on students probably can't be extrapolated.
2009
Using computerized procedures for testing and training abstract comparative relations
Subjects given two comparisons eg A>B and B>C and have to report what mapping from A,B,C to small,medium,large can be deduced. Success rates between 50% and 100% depending on class of problem.
10 subjects. Three sessions. Small but significant increase in performance over time.
10 subjects. Replaced middle session with 'training session' - same interface but explains answers. Near 100% success rates on last session.
Good Programmers: Nature or Nurture? (The bed of Procrustes)
General discussion of nature vs nurture as it pertains to psychometrics. Doesn't really say anything specific about programming.
Types of Cooperation Episodes in Side-by-Side Programming
Observation of 10 grad students learning Java. GT concepts again.
Software Architects: A Different Type of Software Practitioner
Interviewed software architects about projects. Found that they weren't really focused on the projects so the interviews were pointless.
Mining Programming Language Vocabularies from Source Code
Text-mining JDK. Doesn't seem to have any new results from their past paper.
Meta-analysis of the effect of consistency on success in early learning of programming
6 attempted replications of consistent-mental-model-predicts-programming-ability experiment.
First failure had too very high pass rates - almost all of the students were consistent. Second failure was a test given after the course - expect that a programming course should teach students to pass the test (this objection doesn't actually seem to me to make sense).
Improved protocol, detailed in previous paper.
Next four replications from author and collaborators. All seem to be somewhat successful.
Initial Exploration of Eye Movements in Collaborative Work: Case Pair Programming
Eye-tracking during pair programming. Method and results are not really clear.
Further Observation of Open Source Programmers’ Information Seeking
Yet more mailing list mining. Low response rate. No other interesting observations.
Examining the Structural Features of Systems Developed in C++ and Java
10 C++ and 10 Java projects out of top 100 sourceforge downloads. Conclusions seem to be far too strong given the metrics examined eg low number of protected methods -> not enough use of information hiding.
Design Requirements for an Architecture Consistency Tool
Reflexion modeling for fighting architectural drift. 2 year longitudinal study at IBM Dublin. Discovered many violations of the model, but they generally weren't removed. Designed a CI version of the tool to catch violations as they happen.
Concrete Thoughts on Abstraction
Tries to break effective use of abstraction down into subskills.
Computer Code as a Medium for Human Communication: Are Programming Languages Improving?
12 subjects given code comprehension task in either Java or Scala under eye-tracker. The dense Scala code was more quickly understood.
Communication in Testing: Improvements for Testing Management
Survey answered by 23/60 professionals in single company. Reported poor overall visibility of test state, poor coordination between departments.
Cognitive levels and Software Maintenance Sub-tasks
6 professionals talk-aloud in maintenance tasks at work. Tries to code utterances into Bloom taxonomy. Not clear what they are looking for.
Can Named Ranges Improve the Debugging Performance of Novice Spreadsheet Users?
21 students asked to debug spreadsheet that uses named ranges. Uses previous experiment as control. Worse performance than control.
Tries to justify use of separate control by comparing error distribution to control group in a different (and properly randomized) experiment.
An Evaluation of inline source code browsing
Tool opens source code inline instead of jumping to different file.
7 subjects given various comprehension tasks. 14% faster with inline. No significance test.
A Course Dedicated to Developing Algorithmic Problem Solving Skills - Design and Experiment
Problem-solving course. Students reportedly approve. No other evaluation.
2010
A Cognitive Neuroscience Perspective on Memory for Programming Tasks
Basic overview of memory models.
A Logical Mind, not a Programming Mind: Psychology of a Professional End-User
Case study - 3 years, electronic patient record system in ICU. Customised in the field by users. Hired a professional programmer for 5 days to contrast their mental model with users.
Modifications made live with little version control tooling. Users willing to make long-term learning efforts, but only when there is a clear need/payoff. Not interested in understanding for it's own sake.
Programmer spent a lot of time trying to teach inheritance and talking about OOPy models of cars. Users completely exasperated at this apparent waste of time.
Bricolage Programming in the Creative Arts
Philosophizing.
Characterizing Comprehension of Concurrency Concepts
UML diagrams for concurrency. 15 students given comprehension test on concurrent system. Miscomprehensions are tangled chains of mistakes. Tries to categorize them by semantic level at which they occur.
Tendency to write tests that confirm hypotheses rather than refute them.
88 subjects drawn from 4 companies and from grad school. Watson's rule discovery task and selection task. Students did better. Don't see a control for IQ or similar.
Empirically-Observed End-User Programming Behaviors in Yahoo! Pipes
Mined 30k pipes. Most pipes are DAGs (ie no use of looping constructs). Most pipes use a small subset of the available constructs. Most pipes are hardwired - number of exposed parameters fits exponential distribution.
39 students in control group taught with trace tables. 61 students taught with diagrams of memory layout. Different teachers. (Numbers suggest not randomly assigned?).
Simple programming exam. Tiny but significant effect size.
Interviewing XP programmers to determine their goals. No attempt to determine reliability or validity of their methods.
Evaluating Scratch to Introduce Younger Schoolchildren to Programming
Case study with Scratch. Given LOGO test at middle and end - small improvement. Main upside is more enthusiasm, less frustration (compared to?).
Liveness in Notation Use: From Music to Programming
Breaks liveness into levels. Compares different tasks in programming and music.
Neat diagrams of feedback loops in various systems.
Perceived Self-Efficacy and APIs
Designed self-efficacy questionnaire for APIs. Don't understand their attempt to prove that the test is reliable. They note that their other experiments have terrible power.
Project Kick-off with Distributed Pair Programming
Case study of distributed pair programming. Small number of sessions, small number of subjects.
Students’ Early Attitudes and Possible Misconceptions about Programming
Ask students about recollections of efficacy at various points in time. Results are confused.
Teaching Novice Programmers Programming Wisdom
List of heuristics novices might benefit from.
The Construction of the Concept of Binary Search Algorithm
Teaching binary search. Same as previous paper, I can't figure out what the contribution is.
The use of MBTI in Software Engineering
Looks at previous studies of distribution of MBTI types in devs.
Usability Requirements of User Interface Tools
Programming interactive apps is hard. Proposed advances from academia have not taken off. Big list of properties that make interactive software different to purely computational software.
2011
Study attitudes and behaviour of CS1 students – two realities
IACHE inventory given to 72 high school students in Brazil and 258 in Portugal. No conclusive differences between the two.
The cognitive dimensions questionnaire: adapting for non-expert users
Specializing CD questionnaire to POS software.
The influence of class structure on program comprehension
211 undergrads from 3 schools. Comprehension test on OOPy and non-OOPy programs in VB and Java. Students given non-OOPy did worse, but looking at the graph the only major difference is in the 'Class' category of questions, which seems like an obvious conclusion?
The programming-like-analysis of a innovative media tool
Media designers often need to reuse 'code' eg designing same dvd menu for many different markets. Presents a tool that separates style from content.
Understanding program complexity: an approach for study
Proposes trying to relate eye-tracker data to complexity metrics.
Useful but tedious: An evaluation of mobile spreadsheets
Subjects asked to query or edit typical office spreadsheets on a phone. Problems with cell selection, character selection, inconsistency between platforms, having to focus on keyboard while editing.
User configurable machine vision for mobiles
Software that lets users train classifier on their own visual syntax, map properties of syntax to synth inputs and then play music by pointing the camera at notation.
Many usability complaints.
Proposes a sort of high-level virtual machine with visualization + replay as a teaching tool.
What makes software engineers go that extra mile?
Interviews with 13 professionals. Motivated by the work itself, and the aesthetics for their code. Demotivated by external obstacles to producing satisfying code.
No body
Systematically Improving Software Reliability: Considering Human Errors of Software Practitioners
CS should borrow ideas from human error research.
A case study on the usability of NXT-G programming language
12 students of various ages. Even experienced programmers struggled with the tasks. Loop blocks confused most subjects.
An empirical study of the influence of OCL on early learners
36 students taught an OOPy UML. When asked to choose between two models, more preference for simple models when expressed as UML vs informal.
Automatic algorithm recognition based on programming schemas
Classifier for sort algorithms with 87% accuracy on student submissions. Wants to improve it so it can give automatic feedback to students.
(One of the MIT MOOCs uses a semi-interactive classifier to help grade and give feedback on the huge number of student submissions, so it's plausible in practice.)
Class participation and shyness: affect and learning to program
CS students are often shy, and report difficulties with asking questions in class or asking for help from tutors.
Applying CD to design to a language.
Investigation of qualitative human oracle costs
Make generative testing map to more concrete natural inputs where appropriate eg random names rather than random strings. No evaluation yet.
Measurement and visualisation of software timing properties
Timing visualisation tool for hard real-time. Proposes researching such.
On the cognitive foundations of modularity
Trying to relate OOP to cognitive uses of abstraction, I think?
Origins of poor code readability
Speculates on reasons for poor code. Nothing surprising.
Programming with the user in mind
Live Sequence Charts. Seems like programming in terms of user stories.
Interviews with students suggest that it leads them to view the system from the outside rather than from the inside.
Robot dance: edutainment or engaging learning
Single session outreach. 135 school students in total.
Pre/post programming tests show improvements in most areas, but suspicious that it had to be broken down into areas to isolate the negative area.
Focus on knowledge seems weird for outreach anyway, would have expected them to survey attitudes.
Self-Reporting emotional experiences in computing lab sessions: an emotional regulation perspective
Students report emotional state in class either via desktop widget or via a hand-held ball gadget thing. Students liked the ball as a fidget toy and as a signaling mechanism.
I kind of want one.
2012
A Field Experiment on Gamification of Code Quality in Agile Development
Tool that assigns reputation to code, and then to programmers based on their interaction history with that code.
Past experiments found correlations of .64 and .88 with actual reputation (from surveying peers?).
Field study in postgrad lab. Does not appear to increase actual code quality. Students reported perception of unfairness and opacity. Reputation score not seen as a high priority.
A Study about Students’ Knowledge of Inductive Structures
Piaget strikes again. Still have no idea what I'm supposed to be learning from these stories.
Computer Anxiety and the Big Five
Computer Anxiety Rating Scale and five-factor personality test given to >100 biz students. Agreeableness and emotional stablity negatively correlated with computer anxiety, explaining 38% of variance.
Conducting Field Studies in Software Engineering: An Experience Report
Common problems with field studies. Some are surprising, eg the need for extension cables.
Evaluating application programming interfaces as communication artefacts
Not clear.
Evaluation of Subject-Specific Heuristics for Initial Learning Environments: A Pilot Study
Proposes list of qualities to bear in mind when designing learning environments.
Gave either old list or new list to 9 students and ask them to do usability reviews. No clear conclusions.
Exploring the design of compiler feedback
Prototype compilers that give feedback on possible performance problems. Hard to evaluate because users mostly disabled the popups.
Gaze Evidence for Different Activities in Program Understanding
Pair programming under eye-tracking. Different gaze patterns between experts and novices.
In search of practitioner perspectives on ‘good code’
Software craftmanship.
Proposes testing whether restricted focus tools alter programmers behavior.
92 students get normal instructor. 14 volunteer students get MTL tool instead. Course score very slightly higher for volunteers.
Observing Mental Models in Novice Programmers
Adjusted consistent-model test for online testing.
126 high school students in UK. Almost a third scored highly, mostly with an underlying model of parallel execution of lines. Post-test interviews confirmed the models recognized by the test by were accurate. Students who were labeled unrecognized reported multiple models, switching models partway or 'shrug'.
92 undergrad students in Mexico. Around half marked algorithmic, similar to original experiment.
Interviews used to refine questions and marking scheme for future tests.
Schema Detection and Beacon-Based Classification for Algorithm Recognition
Expanding their algorithm classifier. On 222 implementations from textbooks and webpages, gets 94% accuracy.
Sketching by Programming in the Choreographic Language Agent
Interesting. Not sure what to summarize.
Some Reflections on Knowledge Representation in the Semantic Web
Semantic web ontologies organized around strict hierarchies. Probably not a good map to human knowledge.
Teaching Novices Programming Using a Robot Simulator: Case Study Protocol
Planning to use virtual robots for teaching.
Thrashing, Tolerating and Compromising in Software Development
Interviews with 7 devs from a single (academic?) institution. Tries to categorize response to errors. Thrashing - undirected, random. Tolerating - just ignore the error. Compromising - hack something together for the sake of progress.
2013
I don't know why there is only one paper listed for 2013.
Not totally clear on what meta-ethnography entails. Description is surprisingly similar to the research process described in How To Read A Book.
2014
Proposed data-collection PhD project.
Google Sheets v Microsoft Excel: A Comparison of the Behaviour and Performance of Spreadsheet Users
Biz students given spreadsheet tasks. Text and number entry was faster in google sheets, eyeballed at about 2/3 mean time. Formula entry faster in Excel.
Kind of a pointless comparison.
Neo-Piagetian Theory and the Novice Programmer
No new results in here.
Self-explaining from Videos as a Methodology for Learning Programming
Proposed PhD project.
Interviews with devs at Google and Autodesk on their use of VCS. Common themes: high understanding of concepts, ritualized interaction staying with narrow paths, signs of fear and uncertainty. (Slapping down the oft repeated assertion that git is only confusing if you don't understand the underlying model).
Speculates that dependencies on undisplayed state (eg staging area, current branch) and premature commitment (eg many operations are potentially destructive to the working tree) are the main culprits, which is why existing guis don't alleviate the problem.
A cognitive dimensions analysis of interaction design for algorithmic composition software
Suggests representation of time as the most problematic area.
Activation and the Comprehension of Indirect Anaphors in Source Code
Proposed experiment.
Affective Learning with Online Software Tutors for Programming
Two online tutors. >2000 students from 56 schools. Affective learning questionnaire - no significant interactions with gender, race or subject. Male students and caucasian/asian students scored better on pre-tests for arithmetic tutor. Non-CS students improved more between pre- and post-test.
Blinded by their Plight: Tracing and the Preoperational Programmer
Ask students to trace code, and what the code is supposed to do. Identifies a group of students who can trace code and can't explain it. In talk-aloud, these students struggle to move from concrete value to abstract sets.
(Implies that laddering up is a additional skill on top of execution models.)
Cognitive Flexibility and Programming Performance
298 subjects. Task-switching test. Results comparable to similar published tests.
65 students with some experience + 45 novices. Significant correlation between task switching test score and average grade at -.34, but no significant correlation with final exam grade or credits received.
Concept Vocabularies in Programmer Sociolects
40 C++ samples from 14 students. Extract identifiers. No correlation between years of experience and number of not-in-stdlib concepts.
Developing Coding Schemes for Program Comprehension using Eye Movements
We don't know how to interpret all this eye-tracking data. Proposes a scheme for developing coding schemes for eye-tracking data.
Educational Programming Languages: The Motivation to Learn with Sonic Pi
12 novices. Given tutorials on either Sonic Pi or Kids Ruby. Questionnaire on motivation and background. Sonic Pi users typed more, recalled more commands. No notable differences in qualitative questions.
Evaluation of a Live Visual Constraint Language with Professional Artists
Anecdotal reports. Not summarizable.
Exploring Core Cognitive Skills of Computational Thinking
Looking for tests that predict computational thinking. Tried D.48 (abstraction, relation, analagy), spatial reasoning test, GATB (arithmetic reasoning and tool matching subsets only).
12 students. Used raw test scores only. Sample too small to obtain significant results, but D.48 and spatial reasoning show correlations ~.5 with exam grades.
Exploring Creative Learning for the Internet of Things era
Project helping 5 artists work with RPi. Frustration with setup cost and lack of portability.
Exploring Problem Solving Paths in a Java Programming Course
101 students in intro course with 100 assignments, broken into 170 tasks. Automated test system collects snapshots every time it is run.
Majority of students build programs up incrementally and pass tests one by one.
Falling Behind Early and Staying Behind When Learning to Program
Similar consistent-model test. 360 students at 2 unis. High and significant correlations with eventual grades.
Ghosts of programming past, present and yet to come
Live programming, computers as personal expression.
Learning Syntax as Notational Expertise when using DrawBridge
Programming environment that supports both direct manipulation, block editing and raw text editing.
21 school students. Taught in 4 groups, each introducing interactions in different orders. Pre/post-test of syntax knowledge.
Analysis is confusing, but conclusion suggests that introducing block editing before text editing was beneficial.
Linking Linguistics and Programming: How to start?
Sociolinguistics? Demonstrates that natural language approaches don't carry over directly.
Noodle, a VPL for blind children. Work in progress.
Reasoning about Complexity - Software Models as External Representations
Distributed cognition. Anecdotal reports from users of NetLogo.
The Object-Relational impedance mismatch from a cognitive point of view
Trying to tease out what people in various domains mean by 'object' by showing them tables of data and asking how many objects are in view.
2015
An empirical investigation of code completion usage by professional software developers
6 devs, first given programming task and then later asked to narrate the recording. Code completion used for checking method names, api exploration, catching bugs (eg if completion list looks wrong, look for bugs in code leading up this line).
Analysing Java Identifier Names in the Wild
Mining names in 60 java projects. Not sure what the point is.
Confidence, command, complexity: metamodels for structured interaction with machine intelligence
Properties that need to be exposed in end-user machine learning tools. How sure is the answer, how well does the program understand the domain, how complex was the method used to arrive at the answer.
Using EEG to measure cognitive load. Not clear how useful it is compared to just asking.
Harmonious Authorship from Different Representations
Describes a programming model meant to allow many different editing representations. Without either examples or formal specs it's hard to understand how it's intended to work.
Improving Readability of Automatically Generated Unit Tests
Trains a readability model for tests. Outperforms generic readability models. Develop optimization process that produces average readability improvement of 1.9%.
Intuitive NUIs for Speech Editing of Structured Content
Proposed redesign of speech-controlled tool for writing math formulae (which is a weird idea in the first place - even between humans face-to-face there is a still a preference for writing formulae).
Hard to find small problems - even experienced programmers can't do as much as they think in 40 min class.
Adults struggle to learn because afraid of / unwilling to make mistakes.
The construction of knowledge of basic algorithms and data structures by novice learners
Again, where is the content.
The dream of a lifetime: an opportunity to shape how our children learn computing
Ideas > tech. Computational thinking > programming. Progress in new UK curriculum.
The impact of syntax colouring on program comprehension
10 subjects under eye-tracker. Mental execution task. Syntax highlighting reduces completion time. Stats are a bit suspect.
Notably, under syntax highlighting there are much fewer fixations on keywords. (Maybe colour enables peripheral vision?)
The impact of Syntax Highlighting in Sonic Pi
10 subjects. Writing and debugging tasks. Significantly faster completion with syntax highlighting (looks like ~25% faster, weird lack of numbers in this section). Programming and musical experience have no significant effect.
Understanding code quality for introductory courses
How to teach students about quality of code. Not much here yet, all looking forward to future work.