Disclaimer: I used to work for Materialize which is one of the systems being compared in this post.
This post covers the internally consistent/inconsistent branch in my map of streaming systems.
The core message of this post is that intuitions from distributed key-value databases don't carry over well to systems which do complex computation. An eventually consistent key-value database might show you old values. An eventually consistent streaming system might show you outputs that are completely impossible for any set of inputs, and might never converge to a correct value as long as new inputs keep arriving.
To regain the intuition from databases we also need internal consistency - a property I'll define below. I'll also cover a few classes of internal consistency failures and demonstrate how to reproduce these in the wild, using ksqldb and flink as examples of internally inconsistent systems and differential dataflow as an example of an internally consistent system.
Running example
To keep things concrete, I'll use the same simple example throughout. It's kind of contrived, but it's tough to find an example that demonstrates all the failure modes and is realistic but is still simple enough to walk through the event interleavings in a blog post. Bear with me.
The input is a stream of 10m transactions, moving money between 10 distinct accounts. The amount of money moved is always $1, to make it easier to eyeball the scale of errors. The transactions contain 60 distinct timestamps (as if produced by some regular batch CDC) and can be out of order by up to 10 seconds.
random.seed(42)
max_id = 10000000
transactions = []
for id in range(0,max_id):
second = ((60 * id) // max_id)
delay = random.uniform(0, 10)
row = json.dumps({
'id': id,
'from_account': random.randint(0,9),
'to_account': random.randint(0,9),
'amount': 1,
'ts': f'2021-01-01 00:00:{second:02d}.000',
})
transactions.append((second + delay, id, row))
transactions.sort()
for (_, id, row) in transactions:
print(f'{id}|{row}')
For systems that support it, the transactions are read with a 5 second watermark to stress handling of late data.
The calculation we want to do is very simple - just tracking the current balance of each account - but it stresses most of the failure modes I'll describe in the next section.
CREATE VIEW credits AS
SELECT
to_account AS account,
sum(amount) AS credits
FROM
transactions
GROUP BY
to_account;
CREATE VIEW debits AS
SELECT
from_account AS account,
sum(amount) AS debits
FROM
transactions
GROUP BY
from_account;
CREATE VIEW balance AS
SELECT
credits.account AS account,
credits - debits AS balance
FROM
credits,
debits
WHERE
credits.account = debits.account;
Outer joins and self joins are often hard to get right in a streaming setting, so let's include a (somewhat meaningless) query that tests both. Since both sides of the join have the same input, the output should never contain null values.
CREATE VIEW outer_join AS
SELECT
t1.id AS id,
t2.id AS other_id
FROM
(SELECT id FROM transactions) AS t1
LEFT JOIN
(SELECT id FROM transactions) AS t2
ON
t1.id = t2.id;
Since money is only being moved around, never created or destroyed, the sum of all the balances should always be 0. This gives us a very clear invariant for detecting consistency violations.
CREATE VIEW total AS
SELECT
sum(balance)
FROM
balance;
This is a very simplified version of code that I've written in a real system where we needed to ensure that no customer had found a series of actions that would create money eg by causing rounding in their favor. If the total was ever non-zero it would trigger an alert.
One thing to note is that this query does not window any of its inputs, putting it firmly on the low temporal locality side of the map where consistency is more difficult to maintain.
Consistency
A system is eventually consistent if when we stop providing new inputs it eventually produces the correct output for the set of inputs provided so far.
A system is internally consistent if every output is the correct output for some subset of the inputs provided so far.
For our example, this means that it would be eventually consistent if total eventually becomes zero after processing all the inputs, and it would be internally consistent if it never outputs a non-zero value for total.
In general, neither one of internal consistency and eventual consistency implies the other:
- Internal consistency allows the system to be have arbitrary processing delays. It also allows dropping input - this is not eventually consistent, but in many applications (eg analytics) it's not a big deal if some small percentage of the data is lost.
- Eventual consistency requires the output eventually becomes correct if inputs stop arriving, but allows the system to produce nonsense outputs as long as inputs are arriving. And if we always have new inputs then it never has to converge to a correct output.
In practice, we usually want both internal consistency and some stronger form of eventual consistency that includes liveness guarantees. We want the system to produce correct outputs and we want some guarantee that every input will eventually be processed.
Let's look at some of the ways we can fail to achieve this.
Failure modes
This is not an exhaustive summary of ways to violate internal consistency, just the main causes I've seen so far.
Combining streams without synchronization
When combining multiple streams it's important to synchronize them so that the outputs of each reflect the same set of inputs.
In our example, if the join between credits and debits is not synchronized then we could be calculating the balance using the current value of credits and the past value of debits, effectively creating money.
This would be internally inconsistent but still eventually consistent - if we stopped adding new transactions the streams would eventually get back in sync again and total would return to 0. But if the input was unbounded and one stream was always ahead of the other then total would never return to 0.
These mergings of streams appear in any sql query that uses the same table more than once, in self-referential calculations like argmax, and in graph traversals like followers-of-followers. They also appear in the best methods I know for compiling sql subqueries into streaming operations.
A very similar problem can occur when handling event-time joins over out-of-order data, where both input streams to the join need to be synchronized by event time. All of the systems below that suffer from synchronization failures will also suffer similar failures for event-time joins.
Early emission from non-monotonic operators
Many streaming operators are logically monotonic - receiving new inputs can only every cause them to emit new outputs. This makes life easy for eventual consistency.
But some operators are non-monotonic - notably outer joins and aggregates. These require much more care.
Let's look at the progress of a single transaction through the example above:
insert transaction(42, 3, 7, 1, '2021-01-01 00:00:11.000')
This transaction causes the total values for credits and debits to change.
delete debits(3, 712)
insert debits(3, 713)
delete credits(7, 422)
insert credits(7, 423)
In order to produce correct outputs, the aggregate for total needs to process the 4 events above atomically. If it processes them one by one, the output will be:
# processing delete debits(3, 712)
delete total(0)
insert total(712)
# processing insert debits(3, 713)
delete total(712)
insert total(-1)
# processing delete credits(7, 422)
delete total(-1)
insert total(-423)
# processing insert credits(7, 423)
delete total(423)
insert total(0)
This leads to 3/4 of the output values being incorrect.
To be internally consistent, total needs to wait until it's seen all the updates that correspond to the original transaction before emitting an output.
Confusing changes with corrections
In the output above, total went through a series of intermediate values before returning to 0. None of these was a correct (or even possible) value for total, but this stream does not distinguish between changes to the correct value and corrections of intermediate outputs.
For eventually consistent queries over the present value it's sufficient to just operate on the latest value. But for queries over the history of the value (eg "was this account balance ever negative") it's not possible to be even eventually consistent unless the stream of updates distinguishes intermediate outputs from correct outputs.
Similarly, at the edge of the system it's not possible to take action on outputs if you don't know which ones are correct. You might email a warning to a customer for going overdrawn on their account, only to later find that this was just a transient inconsistency.
To be internally consistent, there needs to be some way to determine when an output value is correct. This could be in the form of eg progress statements which tell you that the output for a given timestamp will no longer change.
Inconsistent rejections in watermarks
This is more of an edge case, but unlike stream synchronization this class of failures can result in permanent inconsistency that can't be repaired without restarting the whole topology.
In most systems inputs can arrive out of order. Some operations, especially windowed aggregates, need to see all of their inputs before they can deliver a canonical answer. To deal with this we can augment the input stream with watermarks - messages which say "you have now seen all inputs for time <= T".
In practice we often can't guarantee that we have actually seen all inputs, so these watermarks are just inserted after some reasonable cutoff time and we drop any messages that arrive after the watermark.
This in itself does not violate internal consistency, because we're allowed to drop messages. But some streaming systems (notably kafka streams) insert watermarks in individual operators rather than at the edge of the system. This allows different operators to drop different subsets of the input if their stream-times advance differently. This can be caused by seeing different subsets of the input, by seeing the same inputs in a different order, or if some previous operator uses wall-clock timeouts instead of stream-time timeouts. When the output streams from those operators are compared or combined, inconsistency ensures.
To be internally consistent, a streaming system can only reject inputs at the edge, so that all operators are working on data derived from the same set of upstream inputs.
Systems setup
Having looked at some theoretical failures, let's see how often they actually happen in practice.
I tested a variety of popular streaming systems but in the end only a few could easily express the running example. Others lacked support for unwindowed aggregates and joins or, in the case of spark structured streaming, had severe restrictions on their use.
Differential dataflow / materialize
(differential dataflow v0.12.0 | code)
(materialize v0.7.1 | code)
Differential dataflow is a library for writing consistent dataflow programs. As you can see from the code, it's more of a toolkit for implementing streaming systems than something you would enjoy using directly.
It offers time-varying tables with various relational operators. It tracks timestamps for each event and synchronizes joins by timestamp. Watermarks are required at the edge of the system and are used to control emission from non-monotonic operators.
For the test, I read inputs from a file and write outputs to files. When reading inputs I arbitrarily chose to use 1000 transactions per batch. I also use a watermark trailing 5 seconds behind the latest input.
The output from a differential dataflow collection contains a stream of inserts, deletes and watermarks.
$ head -n 20 differential-dataflow/original-results/balance
no more updates with timestamp < 1609459195000000000
no more updates with timestamp < 1609459196000000000
no more updates with timestamp < 1609459197000000000
no more updates with timestamp < 1609459198000000000
no more updates with timestamp < 1609459199000000000
no more updates with timestamp < 1609459200000000000
insert 1x (0, 62) at 1609459200000000000
insert 1x (3, -34) at 1609459200000000000
insert 1x (9, 95) at 1609459200000000000
insert 1x (4, -133) at 1609459200000000000
insert 1x (6, -3) at 1609459200000000000
insert 1x (8, 196) at 1609459200000000000
insert 1x (1, -3) at 1609459200000000000
insert 1x (5, -47) at 1609459200000000000
insert 1x (7, -37) at 1609459200000000000
insert 1x (2, -96) at 1609459200000000000
no more updates with timestamp < 1609459201000000000
delete 1x (0, 62) at 1609459201000000000
insert 1x (0, 214) at 1609459201000000000
insert 1x (3, -66) at 1609459201000000000
Once a watermark has passed for a given timestamp no more updates will be issued. This allows operators to work as soon as they receive input, while still tracking which outputs are consistent. For this test I call consolidate on the outputs, which accumulates and merges redundant updates until the watermark passes them, guaranteeing that it will only ever emit consistent updates.
I've also included code for materialize which is built on top of differential dataflow and operates under the same consistency model, but adds a SQL interface and a range of sources and sinks which handle interaction with external systems, including assigning timestamps and watermarks.
Materialize' current source/sink system is a placeholder, awaiting redesign into orthogonal sql operators. In the meantime the only source offering support for extracting event-time from arbitrary inputs is the CDC protocol, which I was too lazy to emit. So instead I used a file source and did something hacky with the experimental temporal filters feature.
This means that I can't use a watermark and so, unlike differential dataflow, no transactions are rejected for being late. Apart from that materialize behaves exactly like differential dataflow so I won't cover it separately in the results section.
Kafka streams / ksqldb
(kafka streams v2.7.0 | code)
(ksqldb v0.15 | code)
Kafka streams is exactly what is sounds like - a streaming system built around kafka. Ksqldb is built on top of kafka streams and adds support for a dialect of sql.
Both offer streams of events and time-varying tables. Relational joins are available but only offer best-effort synchronization between streams. The best-effortness is controlled by a number of configuration variables, including max.task.idle.ms which is a wall-clock (!) timeout on how long a join operator will wait for matching input. The default value is 0 ms. The best explanation I can find for the actual join algorithm is in this issue. If I understand correctly this means that joins are not eventually consistent - you can have a network hiccup, timeout one side of the join and then never emit those outputs.
Neither tracks watermarks. The authors argue instead for a model of continuous refinement. This makes it impossible to know when it is safe to act on outputs, as they themselves noted when they later added the suppress operator. The suppress operator allows manually suppressing early emissions from non-monotonic operators. It's similar to differential dataflow's consolidate, but since it lacks watermarks it can't guarantee that the output is consistent, only increase the odds. Being per-operator, suppress also exposes similar failure modes to those mentioned in the earlier section on inconsistent rejections in watermarks. There also doesn't appear to be a way to correctly suppress non-windowed outer joins because the output stream doesn't have access to the stream-times of both inputs to the join. The suppress operator is also not yet available in kafka streams.
Unfortunately I haven't been able to convince kafka streams to produce any output for our running example (KAFKA-12594). People are using kafka streams in production so clearly something about my configuration or environment must be unusual. But after several weeks of effort, including conversations on the confluent slack and asking for help on the kafka mailing list, I've been unable to make any progress.
To avoid whatever misconfiguration was plaguing my kakfa streams effort I'm using ksqldb via the docker image provided by confluent which includes zookeeper and kafka and reasonable default configurations for everything. This is what provides all the results below.
The output is a series of key-value pairs. Where there are multiple updates for the same key, each update replaces the previous value. Deleted keys are represented by an update with a null value.
$ head -n 20 ksqldb/original-results/balance
CreateTime:1609459200000 {"BALANCE":-47.0}
CreateTime:1609459200000 {"BALANCE":-49.0}
CreateTime:1609459200000 {"BALANCE":-48.0}
CreateTime:1609459200000 {"BALANCE":-47.0}
CreateTime:1609459200000 {"BALANCE":-58.0}
CreateTime:1609459200000 {"BALANCE":-47.0}
CreateTime:1609459200000 {"BALANCE":-51.0}
CreateTime:1609459200000 {"BALANCE":-55.0}
CreateTime:1609459200000 {"BALANCE":-59.0}
CreateTime:1609459200000 {"BALANCE":-39.0}
CreateTime:1609459200000 {"BALANCE":-47.0}
CreateTime:1609459200000 {"BALANCE":-58.0}
CreateTime:1609459200000 {"BALANCE":-55.0}
CreateTime:1609459200000 {"BALANCE":-48.0}
CreateTime:1609459200000 {"BALANCE":-49.0}
CreateTime:1609459200000 {"BALANCE":-51.0}
CreateTime:1609459200000 {"BALANCE":-59.0}
CreateTime:1609459200000 {"BALANCE":-47.0}
CreateTime:1609459200000 {"BALANCE":-39.0}
CreateTime:1609459200000 {"BALANCE":-47.0}
Naturally the only option for ksqldb is to use kafka sources and sinks. I pipe the input transactions into kafka-console-producer and read from the sinks with kafka-console-consumer.
Flink
(flink v1.12.2 | code)
Flink is split into two apis - the datastream api is strongly focused on high-temporal-locality problems and so can't express our running example (EDIT see updates at end), whereas the table/sql api offers time-varying tables with all the familiar relational operations.
Like differential dataflow flink tracks event time and watermarks from the edge of the system, but unlike differential dataflow it doesn't use them for all operations. For much of the table api the situation appears to be the same as kafka streams' continual refinement model.
The file source appears to load the current contents of the file in a single batch and then ignore any future appends, so it's not usable for testing streaming behavior. Instead I used kafka for both sources and sinks, with the same setup as for ksqldb. I convert the outputs to streams before sinking to ensure all updates are captured. I also set a 5s trailing watermark on the transactions input.
The output is a series of inserts and deletes for key-value pairs.
$ head -n 20 flink-table/original-results/balance
insert 7,16.0
insert 6,10.0
insert 5,8.0
insert 4,6.0
insert 9,12.0
delete 7,16.0
insert 3,9.0
insert 7,17.0
delete 3,9.0
delete 5,8.0
insert 3,8.0
insert 5,9.0
delete 9,12.0
delete 4,6.0
insert 9,11.0
insert 4,7.0
delete 3,8.0
delete 9,11.0
insert 3,7.0
insert 9,12.0
Results
accepted_transactions
For each system I immediately dump the inputs back out to disk to see what made it in.
I set up differential dataflow to reject any transactions that come after the 5s watermark, which is about 1/3rd of the dataset.
$ wc -l differential-dataflow/original-results/accepted_transactions
6401639 differential-dataflow/original-results/accepted_transactions
Flink also has a 5s trailing watermark, but it doesn't reject any inputs in non-windowed computations.
$ wc -l flink-table/original-results/accepted_transactions
10000000 flink-table/original-results/accepted_transactions
Ksqldb doesn't have watermarks at all.
$ wc -l ksqldb/original-results/accepted_transactions
10000000 ksqldb/original-results/accepted_transactions
When I was experimenting with kafka streams, I sometimes found missing rows in accepted_transactions. Hans-Peter Grahsl kindly explained that this was because:
- When kafka streams writes back to kafka it uses the event time, if set, as the kafka log timestamp.
- My data generator used fixed timestamps which by this point were several months in the past.
- Unless explicitly specified kafka defaults to a 7 day retention period, leaving it free to non-deterministicly garbage collect the
accepted_transactionstopic.
Explicitly setting an unlimited retention period resolved this.
outer_join
The output of this view should never contain nulls because both sides have the same set of ids.
$ grep -c '\N' materialize/original-results/outer_join
0
If we try this in flink it complains that the input tables contain an event-time column which must be used. There are two ways to resolve this.
Drop the event-time column:
tEnv.executeSql(String.join("\n",
"CREATE VIEW outer_join_without_time(id, other_id) AS",
"SELECT",
" t1.id, t2.id as other_id",
"FROM",
" (SELECT id FROM transactions) as t1",
"LEFT JOIN",
" (SELECT id FROM transactions) as t2",
"ON",
" t1.id = t2.id"
));
sinkToKafka(tEnv, "outer_join_without_time");
Or add the event-time column to the join constraint:
tEnv.executeSql(String.join("\n",
"CREATE VIEW outer_join_with_time(id, other_id) AS",
"SELECT",
" t1.id, t2.id as other_id",
"FROM",
" transactions as t1",
"LEFT JOIN",
" transactions as t2",
"ON",
" t1.id = t2.id AND t1.ts = t2.ts"
));
sinkToKafka(tEnv, "outer_join_with_time");
The version without the event-time column behaves like I would expect from an eventually consistent system. Most keys initially appear with a null, which is then retracted and replaced by the correct value.
$ tail flink-table/original-results/outer_join_without_time
insert 9956971,9956971
insert 9926009,null
delete 9926009,null
insert 9926009,9926009
insert 9878245,null
delete 9878245,null
insert 9878245,9878245
insert 9845139,null
delete 9845139,null
insert 9845139,9845139
$ grep insert flink-table/original-results/outer_join_without_time | grep -c null
8552649
$ grep insert flink-table/original-results/outer_join_without_time | grep -cv null
10000000
The version with the event-time column is surprising.
$ grep insert flink-table/original-results/outer_join_with_time | grep -c null
4439927
$ grep insert flink-table/original-results/outer_join_with_time | grep -cv null
5560073
$ grep -c delete flink-table/original-results/outer_join_with_time
0
Many of the rows appear with a null that is never retracted. Lincoln Lee explains that this is the expected behavior for rows which arrive after the watermark.
I don't think this explanation is complete. The number of nulls varies between runs, even though the event-times are fixed, and never matches the number of rows which actually fall after the watermark. Perhaps there is some additional source of non-determinism in the join implementation?
Ksqldb also has some interesting behavior. It doesn't allow obvious self-joins but we can trick it with a single level of indirection to see what happens. As expected, it emits some nulls and later replaces them.
$ wc -l ksqldb/original-results/outer_join
10084886 ksqldb/original-results/outer_join
$ grep -c null ksqldb/original-results/outer_join
36032
But these numbers don't add up. What's going on?
$ grep -v null ksqldb/original-results/outer_join | cut -d':' -f 3 | sort -h | uniq -c | sort -h | tail
2 "9991"}
2 "99911"}
2 "9992"}
2 "99921"}
2 "99923"}
2 "9993"}
2 "99931"}
2 "99947"}
2 "99950"}
2 "99988"}
Some of the rows are updated twice! This isn't actually wrong - the second update is just a noop. But I can't imagine what causes it.
credits / debits
There are 60 distinct timestamps and 10 accounts in the input data. That means that in a system that withholds output from non-monotonic operations like sum we should get 600 updates to credits and debits.
$ grep -c insert differential-dataflow/original-results/credits
600
$ grep -c insert differential-dataflow/original-results/debits
600
Whereas flink updates the sum on every transaction.
$ grep -c insert flink-table/original-results/credits
10000000
$ grep -c insert flink-table/original-results/debits
10000000
Ksqldb doesn't wait for complete inputs either, but it seems to have some non-deterministic internal buffering that allows it to avoid emitting all the intermediate results.
$ wc -l ksqldb/original-results/credits
3450 ksqldb/original-results/credits
$ wc -l ksqldb/original-results/debits
3440 ksqldb/original-results/debits
This demonstrates that flink and ksqldb don't wait for all the inputs to arrive at a given timestamp before updating the sum, so they will be subject to the 'early emission from non-monotonic operators' failure mode.
balance
Like credits and debits we would expect 600 updates to balance - 1 update for each of 60 distinct timestamps and 10 accounts.
$ grep -c insert differential-dataflow/original-results/balance
599
Except that it turns out that in one timestamp, for one account, the balance at the beginning and end of the timestamp was the same so differential dataflow doesn't emit an update.
Flink is again prolific. We can see that it doesn't synchronize the two inputs to the join - almost every update in either credits or debits leads to an update in balance.
$ grep -c insert flink-table/original-results/balance
18999012
Ksqldb behaves similarly.
$ wc -l ksqldb/original-results/balance
6515 ksqldb/original-results/balance
This demonstrates that flink and ksqldb are emitting join results are inputs arrive and without coordination, so they will be subject to the 'combining streams without synchronization' failure mode.
total
The total is always 0, so differential dataflow has only a single insert at the first timestamp.
$ grep insert differential-dataflow/original-results/total
insert 1x ((), 0) at 1609459200000000000
The remainder of the output is a series of progress reports. These tell downsteam consumers that all the inputs up to that point have been processed and there are no further changes. Otherwise it's impossible to tell the difference between "nothing changed" and "massive gc pause".
$ tail differential-dataflow/original-results/total
no more updates with timestamp < 1609459245000000000
no more updates with timestamp < 1609459246000000000
no more updates with timestamp < 1609459247000000000
no more updates with timestamp < 1609459248000000000
no more updates with timestamp < 1609459249000000000
no more updates with timestamp < 1609459250000000000
no more updates with timestamp < 1609459251000000000
no more updates with timestamp < 1609459252000000000
no more updates with timestamp < 1609459253000000000
no more updates with timestamp < 1609459254000000000
Flink multiplies the outputs yet again, with almost every update of balance leading to two updates in total - another example of early emission from a non-monotonic operator.
$ grep -c insert flink-table/original-results/total
37978385
As with the outer join, there was the option of either erasing the event-time column or propagating it through the calculation (I had to do this manually in a few places as eg GROUP BY hides the column). The results are very similar either way though.
Only a tiny fraction of the updates are for the correct output.
$ grep -c 'insert 0.0' flink-table/original-results/total
13325
The behavior over time is fascinating. This graph is for a single run, with one point for each output. But flink seems to oscillate rapidly between a number of stable attractors, creating the appearance of multiple lines overlaid on one another. I don't yet understand the reason for that.
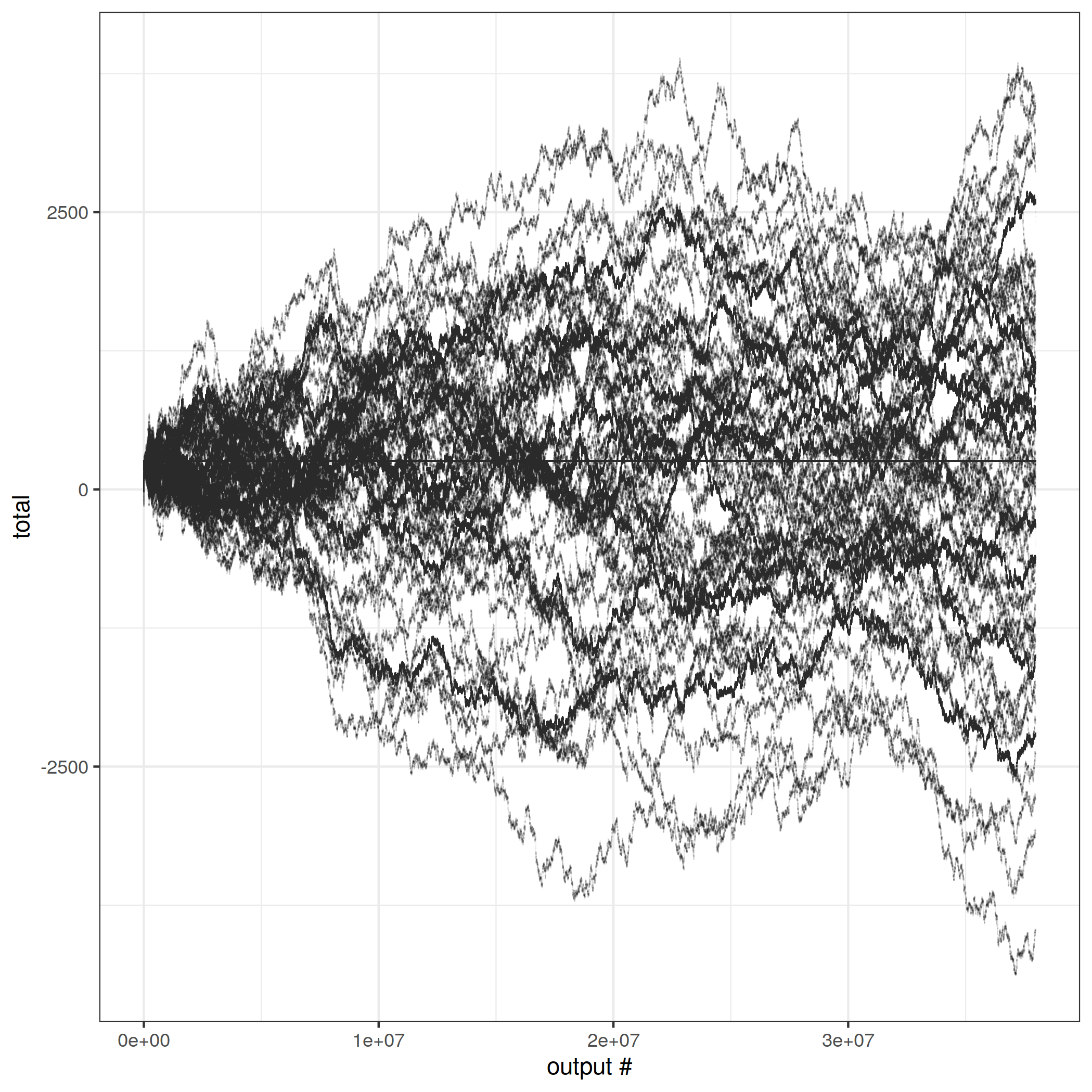
Also striking is that horizontal line just above 0. It's not an artifact. Here is a crude histogram.
$ grep insert flink-table/original-results/total | cut -d' ' -f 2 | sort -h | uniq -c | sort -h | tail
17302 207.0
17363 149.0
17380 157.0
17437 158.0
17564 156.0
17576 151.0
17702 154.0
17709 153.0
17802 152.0
10000767 256.0
26.3% of the updates are the number 256! The actual number varies from run to run, but in each run there is always one single number which has a huge frequency spike compared to the others. I have no idea what causes this.
The final output is correct though, so at least it is eventually consistent.
$ tail flink-table/original-results/total
delete 659.0
insert 2.0
delete 2.0
insert -836.0
delete -836.0
insert 1.0
delete 1.0
insert -1755.0
delete -1755.0
insert 0.0
Ksqldb has less updates due to its earlier coalescing in credits and debits.
$ wc -l ksqldb/original-results/total
340 ksqldb/original-results/total
None of the outputs are correct until the last.
$ grep -F ':0.0' ksqldb/original-results/total
CreateTime:1609459259000 foo {"KSQL_COL_1":0.0}
The absolute error is even larger than flink. I'm not sure how much to read into that, given how much these outputs could depend on subtle details of timing.
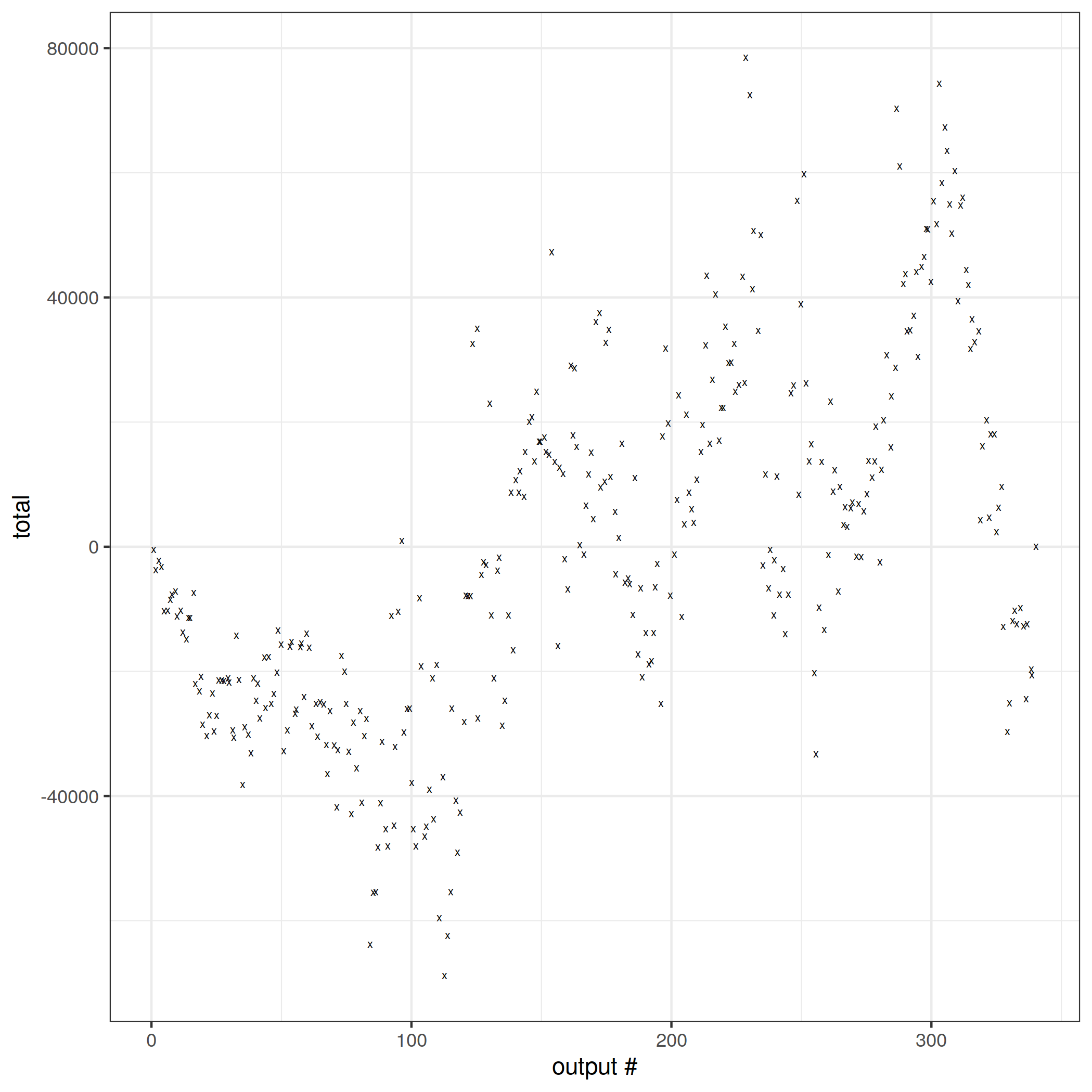
The behavior for both flink and ksqldb is a result of the previous failures in credits, debits and balance, but also demonstrates 'confusing changes with corrections' because the incorrect outputs for total are not marked as such.
total (simplified transactions)
In both graphs the total error seems to be increasing over time. But this is probably because the absolute values in balance are increasing due to the random walk. To get a better picture of the dynamics I made a simplified dataset, where the transactions are all in time order and the transfers shuttle along the accounts in order.
random.seed(42)
max_id = 10000000
for id in range(0,max_id):
second = ((60 * id) // max_id)
from_account = id % 10
to_account = (from_account + 1) % 10
row = json.dumps({
'id': id,
'from_account': from_account,
'to_account': to_account,
'amount': 1,
'ts': f'2021-01-01 00:00:{second:02d}.000',
})
print(f'{id}|{row}')
This means that at every point every account balance should be one of -1, 0, 1.
$ grep insert differential-dataflow/simplified-results/balance | cut -d',' -f2 | cut -d')' -f1 | sort -h | uniq -c
40 -1
68 0
20 1
Flink doesn't quite manage this.
$ grep insert flink-table/simplified-results/balance | cut -d',' -f 2 | sort -h | uniq -c
251 -1.0
477011 0.0
4747211 1.0
4270870 2.0
37 3.0
37 4.0
37 5.0
37 6.0
37 7.0
37 8.0
37 9.0
37 10.0
37 11.0
37 12.0
37 13.0
37 14.0
37 15.0
37 16.0
525131 17.0
5250971 18.0
4725867 19.0
18 20.0
18 21.0
18 22.0
18 23.0
18 24.0
18 25.0
18 26.0
18 27.0
18 28.0
18 29.0
18 30.0
84 31.0
682 32.0
606 33.0
There is a clump around the correct answer, and a separate equally large clump around a completely wrong answer. I don't know why.
The simplified dataset better shows off the stable attractors. Like the previous flink graph, this is a single run and there is one point per output. But all the outputs fall within one of three ranges and the points are so dense that they just look like horizontal bars. The exact bounds of the ranges vary from run to run, but I always see three of them.
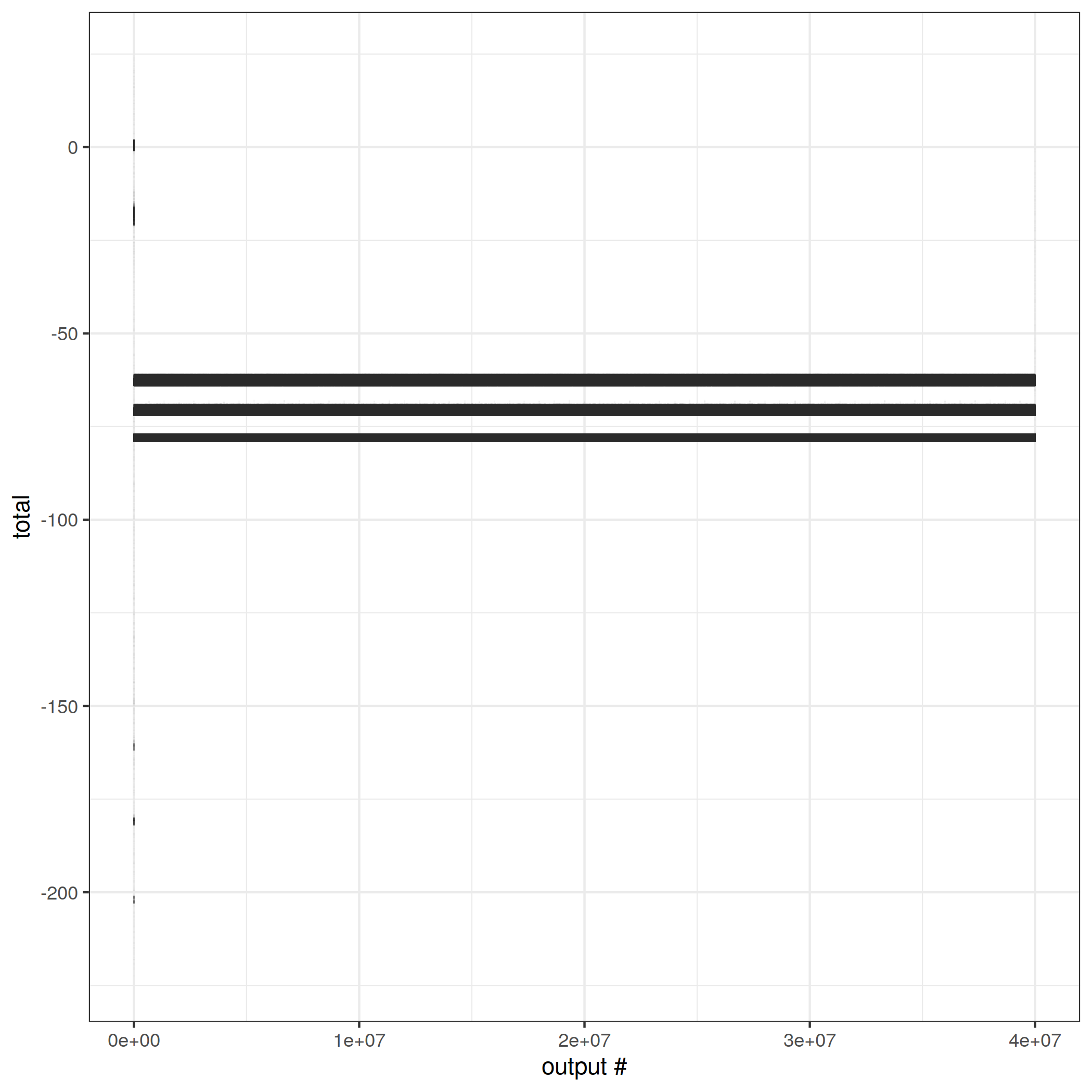
Ksqldb manages an impressively wide spread.
$ cat ksqldb/simplified-results/balance | cut -d':' -f 3 | cut -d'}' -f1 | sort -h | head
-135051.0
-135051.0
-135051.0
-135051.0
-135051.0
-135051.0
-135051.0
-135051.0
-135050.0
-135050.0
$ cat ksqldb/simplified-results/balance | cut -d':' -f 3 | cut -d'}' -f1 | sort -h | tail
2847.0
2847.0
2847.0
2847.0
2848.0
2848.0
2848.0
2848.0
2848.0
2848.0
Where the original dataset caused oscillations, here the total takes a wild downwards dive.
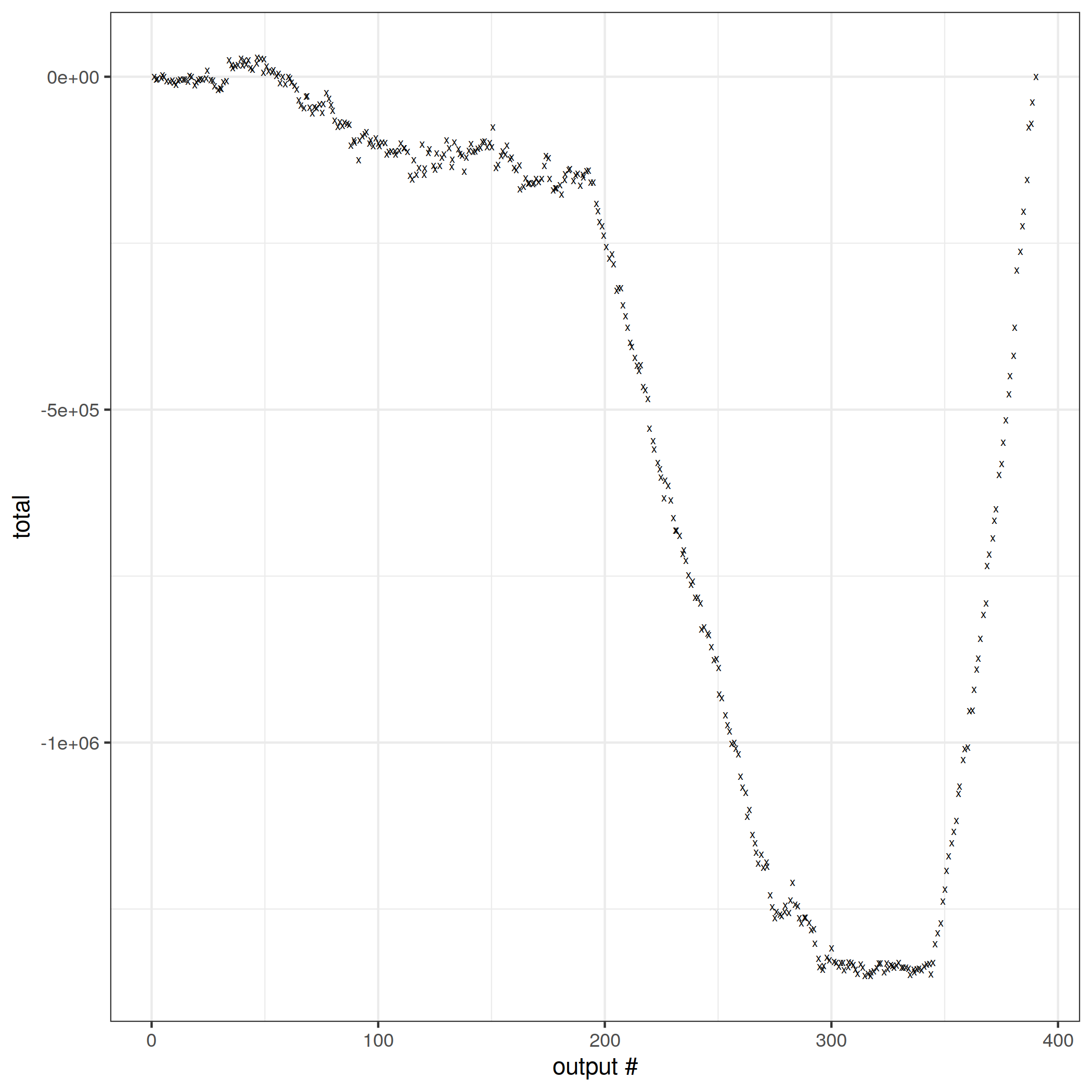
It would be interesting to see if we ran this with a much larger dataset, say a few billion, would it continue its downwards dive or would the error level off somewhere?
Thoughts
I've been aware of the theoretical failure modes for some time. My main takeaway from actually testing them in the wild is that not only are these failures easier to trigger than I expected, the resulting behavior is much more complex than I expected and that I can't currently predict or explain the dynamics. Every one of those graphs presents more questions than answers.
Does this matter?
Historically, streaming systems were mostly used for high-temporal-locality problems like website analytics. These typically:
- have simple topologies, which limits the extent to which errors can multiply downstream
- window their inputs, which allows the output to settle once the window falls past the watermark, and also limits the extent to which errors can propagate into the future
- can often tolerate a bounded amount of error
- often have customers who can't detect errors anyway
Eventual consistency works pretty well for these kinds of problems.
But there is a movement now towards building entire application backends using streaming systems, which are now growing low-temporal-locality operations like unwindowed joins and aggregates to accommodate this usecase. For these kinds of computations we've seen that:
- we might get outputs that are arbitrarily wrong, up to and including breaking program invariants
- the outputs might never converge to correctness
- even if some of the outputs are correct, we won't know which ones
- it is easy to reproduce these failures
We need internal consistency to be able to produce reasonable outputs for these kinds of problems.
We might also want to ask questions like "how many times did the balance for customer X go below 0", but these kinds of historical questions are impossible to answer in a system that doesn't distinguish correct outputs from incorrect outputs, or that emits only a subset of the changes that happened over time.
Many systems also now offer support for declarative languages like SQL, which increases the distance between the developer and the underlying approximations. I challenge anyone to take, for example, this TPC-H query and put a bound on how large the errors can be in an internally inconsistent system.
The effect is similar to undefined behavior in programming languages. In a streaming system that doesn't provide internal consistency almost any operation has the possibility to produce nasal demons in a way that is incredibly difficult to predict or to rule out through testing. Especially since it might depend on load, os scheduling decisions, network delays etc.
I see a parallel in how eg google seems to be moving everything to being backed by spanner, because reasoning about weaker consistency models at scale is just too difficult and too expensive. Internal consistency allows you to pretend that you're just operating a very fast batch system instead of having to reason about all the possible interleavings of updates through your streaming topology.
Testing
The idea of streaming systems is to make it easy to work with unbounded input. But it doesn't appear that most systems actually test behavior under unbounded input - the vast majority of the tests I've looked at only test the final output after everything has settled. Even materialize, which is otherwise pretty heavily tested, does not have many tests which examine intermediate outputs.
A major obstacle is that testing behavior under unbounded input requires specifying what that behavior should be. Many systems don't expect deterministic output and haven't defined the semantics of their operators sufficiently well to judge whether a particular test run is correct not. Internal consistency makes this easier - you can just compare the outputs at each timestamp to your favourite batch system.
The difficulty of testing is compounded by the fact that many system recommend that their users run their own tests in a separate environment which might have different behavior (eg kafka streams recommends using TopologyTestDriver). Instead, I'd strongly recommend both testing intermediate outputs in a staging environment and also figuring out some application-specific invariants that you can monitor in production to at least put a lower bound on the error rate.
Latency
Based on experience with differential dataflow and materialize, I don't expect that guaranteeing internal consistency will have much impact on throughput or horizontal scaling. The amount of metadata that must be tracked is very small and can be amortized over large batches of updates.
There is, however, a strong tradeoff between correctness and latency. A system that is willing to emit potentially incorrect results can emit outputs as soon as it computes them, whereas a consistent system has to wait until it's sure there are no more relevant inputs. The lower latency probably isn't helpful in cases where the potential error is large because if you want to actually act on the output you still need to wait until it's correct. But it means that attempting to add internal consistency to an existing system might see pushback because it makes it look worse in benchmarks that don't check the outputs.
It's worth noting though that kafka streams' policy of continuous refinement doesn't allow it to dodge this tradeoff. In fact, the wall-clock timeouts actually make the tradeoff sharper - a system with watermarks can emit outputs as soon as it gets the watermark, whereas kafka streams always has to wait for the timeout. This probably explains why the default value of max.task.idle.ms is 0 - it would otherwise look terrible in benchmarks.
Flink has systems for dealing with early emissions (triggers) and late-arriving data (allowed lateness). At the moment these open paths to inconsistency because they aren't distinguished from regular outputs, but this seems like something that is possible to implement in an internally consistent way.
Frank McSherry recently demonstrated using bitemporal timestamps in differential dataflow. This effectively allows having multiple waves of watermarks, each of which generates an internally consistent set of outputs which can be distinguished from each other by the bitemporal part of their timestamp. This seems like a neat solution, but I haven't yet tested the performance impact of indexing bitemporal timestamps.
If I was designing a system from scratch I'd be tempted to allow multiple waves of watermarks from the beginning - similar to flink's triggers but propagating through operators and controlling consistency like differential dataflow's watermarks. This would allow emitting early outputs and handling late inputs without risking internal inconsistency and without tackling the problem of indexing bitemporal timestamps.
As a side point, it's noticeable in flink that many joins and aggregates often produce 2 output events for every input event. If we chain many of these operators together in a complex computation we might start thrashing on exponentially increasing numbers of updates. In deep graphs it may actually be faster overall to wait at each operator long enough to merge redundant updates.
What to do?
At minimum I'd like to see existing systems actually document what consistency guarantees they provide and explain the kinds of anomalies that could be observed. It was very difficult for me to determine this from the existing documentation and marketing. It's also pretty clear from conversations with other developers that a lot of people aren't aware that the outputs might be impossibly incorrect, not just out of date.
We also need to better understand the range of possible behavior. Things I didn't even begin to explore here:
- What kinds of queries can produce incorrect outputs?
- How long do we have to wait to be sure that a given output is correct?
- How does the rate of inputs affect the number of incorrect outputs?
- What kind of bounds can we place on the size of errors?
- How is this affected by operating conditions eg if my system is working fine today, can I be sure it won't start emitting incorrect outputs tomorrow if the network has a hiccup or if I change the cpu scheduler?
Ideally the behavior would be sufficiently well defined that it's possible to write tests that examine intermediate outputs, because those are the outputs that real deployments will experience. That doesn't necessarily mean going all the way to internal consistency - there may be room for looser consistency models that still provide useful constraints on behavior. But eventual consistency alone does not provide any useful constraints. It's fundamentally a property that talks about bounded inputs and so it's not informative for computations that can't be partitioned into a series of bounded inputs. We need better ways of describing these new systems.
Updates
Flink datastream api
(flink v1.12.2 | code)
I was wrong about the expressiveness of the datastream api. I saw that the provided operators do not include unwindowed joins, do not have a notion of retractions (which prevents chaining aggregates) and are subject to the 'early emission from non-monotonic operators' failure mode. But Vasia Kalavri kindly demonstrated how to implement the example in an internally consistent way by using ProcessFunction to build custom operators.
$ cat flink-datastream/simplified-results/balance | cut -d',' -f 3 | cut -d')' -f1 | sort -h | uniq -c
60 -1.0
480 0.0
60 1.0
$ cat flink-datastream/simplified-results/total | cut -d',' -f 3 | cut -d')' -f1 | sort -h | uniq -c
60 0.0
The operators for credits, debits and balance accumulate the amount changed per key per timestamp and emit the accumulated value when the watermark passes each timestamp. The output is a stream of changes to the value, not the value itself, which avoids the need for a notion of retractions. If we wanted to see the actual value we'd need an additional sum to reassemble it.
The balance calculation also makes use of the fact that the join in this example is contrived and can be replaced with a union. It seems possible to implement a true join operator in a similar fashion though.
I think the layering of apis is similar to differential:
- flink datastream api ~ timely dataflow
- flink table api ~ differential dataflow
The lower layer handles communication, distribution, and tracks all the metadata needed to build consistent systems. The upper layer takes declarative programs that operate over time-varying collections and turns them into imperative programs that operate over streams of inserts and deletes. In this example, Vasia is effectively hand-compiling the example into streams.
So, given that the datastream api gives you the tools to build consistent systems, I'm curious as to why the table api doesn't use them. Maybe consistency wasn't a priority when it was designed? Or maybe using the datastream api in this way has some performance impact? I'd love to hear from someone who was involved at the time.
Thanks to Julia Evans and Dan Luu for review, Frank McSherry, Ruchir Khaitan and Brennan Vincent for help with differential dataflow and materialize, Matthias Sax for help with kafka streams, Aljoscha Krettek for help with flink, numerous folks on the kafka and flink bug trackers for patiently investigating various misfiled issues and Vasia Kalavri for adding the flink datastream example.