Focused mostly on data layout and query execution. Query planning seems more or less the same as OLTP systems, and I'm ignoring distribution and transactions for now. Also see my full notes here.
It was hard to figure out what systems are even worth studying. There is so much money in this space. Search results are polluted with barely concealed advertising (eg "How to choose between FooDB and BarDB" hosted on foodb.com) and benchmarketing. Third-party benchmarks are crippled by that fact that most databases TOS prohibit publishing benchmarks. Besides which, benchmarking databases is notoriously error-prone.
Luckily Andy Pavlo decided to focus on teaching OLAP databases this year, covering:
On top of that I added, arbitrarily:
- HyPer and Umbra
- SingleStore
And also some diversions into the ecosystems around Arrow / Parquet / ORC.
Notably missing are:
- SQL Server and SAP Hana - I couldn't find recent (ie <5 years) material on either.
- Clickhouse - not much material available in English.
- TiDB - I couldn't find details about data layout or query execution (eg this empty page).
- AlloyDB - not much public material yet.
- DataFusion and Polars - I'm assuming these won't be very different to Velox.
Even among the systems studied, many are proprietary and publish only the highest-level overview of their architecture. Enough info for marketing material but often missing crucial implementation details like how operators are organized for parallel execution.
The term OLAP covers a huge variety of different workloads, from 1000-node clusters crunching hourly reports over exabytes of data, to scientists interactively examinining gigabytes of data on a laptop. But there is surprisingly little variation between these systems at the level of data layout and execution. It's not clear whether this is because they're all trying to maximise bandwidth on similar hardware and this is the emergent best solution, or because they're all just copying ideas from a few influential systems. But the current investment into reusable execution engines like Velox/DataFusion/Polars and open data formats like Arrow/Parquet/ORC suggests that the workloads really might be that similar.
cold vs hot data
The tradeoffs driving data layouts vary in different parts of a database system. As a rough approximation we can divide the problem into:
- Cold/far data. Probably sitting on disk or in some blob store like S3. Optimized for space usage to reduce storage and bandwidth costs. Typically immutable. Almost always column-based.
- Hot/near data. About to be queried, or being passed between operators in a query plan. We still care about space usage but also need to support random access. Mostly column-based, except for state inside row-centric operators like joins.
cold pax
For cold data everyone does some variant of PAX layout. Rows are grouped together and then within each row group the values are grouped by column.
The standard argument (eg in the orginal paper and on Andy's slides) is that this provides the asymptotic benefits of a column-store while still preserving some spatial locality when materializing rows. I don't think this argument applies to any of these OLAP system though. To maximise IO bandwidth we want each column within the row group to be a multiple of the IO block size (4kb for disk, effectively ~8mb for S3) so that we can read data from that column without wasting bandwidth on data from any other column. But this means that reconstructing a single row will always require one block read per column. We can't get better locality without hurting IO bandwidth for column scans.
If we look at row group sizes in practice:
- SingleStore defaults to 1m rows per group (ref).
- Parquet (used in Delta Lake) recommends row groups of 512mb-1gb (ref).
- Duckdb uses 120k rows per group (ref p38).
- Data Blocks (used in Umbra's predecessor) supports up to 64k rows per group (ref 3.1). BtrBlocks (from the same department) also uses 64k rows per group (ref 3.1).
- I couldn't find any hard details for Snowflake, but for bulk data loading they recommend files of at least 100mb to avoid write amplification, which suggests their internal row groups might be in that order of magnitude (ref).
These are all significant multiples of the IO block size for those systems so there is no meaningful IO locality for rows. So why use row groups instead of storing whole columns?
OLAP databases rely on massively parallel table scans. If we break a column into many self-contained individually-compressed chunks then each worker can operate independently rather than needing a shared IO cache and scheduler to manage access to eg large compression dictionaries. But for queries that scan multiple columns each worker needs to grab chunks for the same set of rows. So we should make sure that we chunk each column in the same way ie by row group.
So far nothing about this requires that all the chunks for one row group need to be stored together. But consider a query like delete from likes where likes.user_id == 42. We scan the user_id to get a list of rows that we need to delete. But what is in that list? How do we identify a row? If we store all the chunks for a row group in the same block, then we can identify a row with (block_address, row_index). But if we store chunks in separate blocks then we need a secondary index structure row_group_id -> [block_address] to locate rows. Besides which, all the chunks for a given row group will be created at the same time and (to maintain the same layouts across columns) compacted at the same time. So storing chunks separately provides no advantages and adds some amount of annoying metadata and coordination.
Another way to think about this: Some early column-stores stored explicit row ids in each column. This allowed each column to have a different layout, but wasted a lot of space. Other early column stores referred to rows by index. This saved space but limited columns to layouts which support efficient random access, making efficient updates difficult. We can think about PAX as a hybrid of these two schemes - store explicit ids per row group but then use indexes within each row group, gaining most of the benefits of explicit ids while significantly amortizing their storage cost.
Often each row group will carry some small metadata to allow skipping blocks during scans. I haven't looked much into this yet.
hot pax
For hot data we still see PAX-like layouts, but with much smaller row groups because we want entire query pipelines (see below) to fit in cpu cache. I couldn't find actual sizes for most of the systems, but:
- DuckDB defaults to max 2k rows per group (ref) and uses an inter-operator cache to ensure groups have at least 64 rows (ref).
- In isolated experiments Kersten et al report the best results with 1k-16k rows per group (ref fig 5).
We also need to be able to append new values and even mutate values (eg for sorting). This requires slightly modifying the formats used for cold data. Eg for strings, cold data can just concatenate all the strings and store a list of lengths, but hot data will want to also store a list of offsets to allow for changing the order without having to rewrite the concatenated strings.
It seems common to switch to row-based formats for state within operators where the access patterns are row-centric (join, group-by). I guess it's better to pay the conversion cost once when building the hash-table rather than paying for poor locality on every lookup and resize?
generic vs specialized compression
It's not unusual to see compression ratios of 4x or better for OLAP data. Cutting your storage and bandwidth costs by 4x is way too attractive to ignore so everyone compresses cold data.
Compression algorithms can be split into generic and specialized. Generic algorithms (eg LZ4) work on arbitrary bytestreams. Specialized algorithms (eg dictionary encoding) require some understanding of the structure of the data, and may only apply to certain data types.
Generic algorithms require decompressing the entire block before using values. Some specialized algorithms (eg dictionary encoding) still allow random access to individual values. Others (eg run-length encoding) only allow streaming access to values.
The data within a row group must be split into blocks before compression. Choosing larger blocks gives compression algorithms more opportunities, leading to better compression ratios. But for algorithms which don't allow random access, larger blocks mean that we have to do more decompression work before accessing an individual row. On the other hand most systems store metadata to allow skipping blocks during scans - smaller blocks mean more fine-grained metadata which leads to more metadata checks but also allow more opportunities to skip blocks.
Allowing each block to use different specialized algorithms depending on the data distribution improves compression ratios, compared to picking a single algorithm per column.
Most specialized algorithms also allow executing some filter operators without first decompressing the data. For example, to execute ... where column = value over a dictionary-encoded column, we first lookup value in the dictionary. If it's not present then we can skip the entire block. If it is present then we can scan the column for the integer code corresponding to value without doing any more dictionary lookups. This is dramatically faster than decompressing and then scanning the decompressed data, and also more amenable to simd.
For cold data most systems apply both one or more specialized algorithms and then some generic algorithm afterwards. But the HTAP systems SingleStore and HyPer avoid generic algorithms - they want to preserve random access so they can build efficient secondary indexes over their cold data.
For hot data most systems use some subset of specialized algorithms which allow operating on encoded data. It's not clear if this applies past the initial scan - is it worth compressing the output of an operator that transforms its input? I imagine not, but I haven't dug through any code to check if anyone does this.
The recent BtrBlocks paper claims that by stacking specialized compression algorithms it's possible to get similar compression ratios to generic compression but with substantially better decompression bandwidth. Their benchmarks are intended to be reproducible - it would be interesting to rerun them with the subset of algorithms that preserve random access to see how much compression ratios suffer.
nested and heterogenous data
For nested data (arrays, structs etc), some systems only support dynamically typed blobs:
- Snowflake has VARIANT/OBJECT/ARRAY types which are stored as binary blobs. The runtime analyzes the blobs to infer types and extract columnar views.
- Redshift has a SUPER type which is stored as a binary blob. It doesn't seem to support equality comparisons on this type (ref), which seems limiting.
Other systems require static types but can use columnar encodings:
- Parquet (and hence databricks) supports nested types using the format described in dremel.
- Velox and DuckDB decompose structs/arrays into nested columns.
SingleStore uses a hybrid layout, with common paths being stored in separate columns and rare paths store in a single blob. Umbra makes brief mention of supporting json values but I can't find details.
Worth noting that the dremel format makes random access very expensive - if we want to evaluate a single path like docs[42].links.backwards[3] I think we have to stream through all the records in a block. On the other hand, it's algebraically closed - every operator consumes and produces data in the same format without ever needing record reassembly.
In the velox/duckdb format, I'm not totally clear how we go from a filter scan on a nested column to a selection vector on a higher level eg select doc where exists(select back from doc.links.backwards where startsWith(back, "http://")). We essentially need to do a reverse lookup on the offset/length column for each entry in the selection vector.
I couldn't find any data formats which support heterogenous columnar data (ie sum types) other than zed's vng. But sum types can be emulated in parquet/velox/duckdb using a struct with a tag field and multiple nullable payload fields.
// intention
Event = enum {
a: A,
b: B,
c: C,
}
// implementation
Event = struct {
tag: enum { a, b, c},
a: ?A,
b: ?B,
c: ?C,
}
Given sufficiently good encodings for nullable columns this might not be terrible?
parallelism
The cloud databases are all pretty cagey about how they parallelize queries. I couldn't figure out anything about Snowflake, Redshift or SingleStore.
Photon seems to rely on the shuffle-based mechanism it inherits from spark. The core idea for shuffle-based parallelism is that the data is partitioned by key and each operator only has to care about it's own partition. When the output of an operator has a different key from the input, a shuffle redistributes data across workers. I haven't looked at their implementation in particular but in older systems this design could make it difficult to balance work. If the data distribution is skewed, some of the workers will have way too much work and will lag behind. ALso depending on the design, all the operators before a shuffle might have to finish before the operators after the shuffle can start, in which case a single slow worker can hold up the whole query.
The single-node systems DuckDB (ref), Velox (ref), HyPer and Umbra all use (more or less) the same high-level architecture described in Morsel-Driven Parallelism. Query plans are trees of operators, through which rows flow.
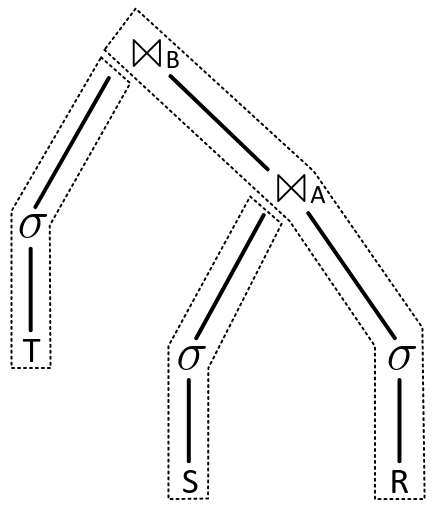
Some operators (eg map, filter) can be executed in streaming fashion. Others (eg join, group) have to wait until one or more of their inputs has supplied all it's data before they can produce output. We can split the plan into pipelines (the dotted lines), each of which starts with a source that produces input rows and finishes with a sink that consumes output rows.
Each worker thread repeatedly:
- Asks a sink for some input rows.
- Passes those rows through all the streaming operators in the pipeline.
- Accumulates the output rows in the sink.
This means that only the source and sink operators need to be aware of parallelism. When the source is a scan each worker thread can do their own independent IO and they only need to coordinate on which byte ranges they read. Often the sink is building up some per-thread state which will be combined when the pipeline is finished, in which case there is no coodination cost for accumulating output rows at the sink.
For multi-node systems some kind of inter-machine communication and scheduling is still needed around sinks, but I don't need to think about that yet.
push vs pull
Some operators don't need all of their input to be computed at all. Eg ... limit 10 or ... where exists (...). We need some way for them to signal when they have seen enough data.
In pull style, each operator exposes a method that produces rows and may also call this method on it's children:
class LimitOperator:
def get_rows(self):
if self.limit == 0:
# Don't waste time computing rows that we'll never return
return []
rows = self.child.get_rows()
rows = rows[0:self.limit]
self.limit -= rows.len
return rows
In push style, each operator exposes a method that accepts some input and returns some output, along with an enum indicating whether it wants more inputs.
class LimitOperator:
def operate(self, rows_in):
rows_out = rows_in[0:self.limit]
self.limit -= rows.len
status = (self.limit == 0) ? "finished" : "want_more_input"
return (status, rows_out)
Some external system is responsible for calling this method and passing data between operators.
Pull style has long been the default for OLTP databases, going all the way back to Volcano. But push style seems to be ubiquitous for OLAP and HTAP systems (except for Photon, which is perhaps limited by backwards compatibility with spark?). Notably DuckDB started with pull style and ended up doing a complete rewrite to push style (ref).
The main problem with pull style is that each operator is responsible for scheduling it's own children. But to support work-stealing, async I/O and query cancellation we really want one global scheduler with visiblility of the whole query.
Note that while the example code above is pretty simple, in general the change from pull style to push style looks a lot like a manual version of what a compiler does when transforming async code to state machines. Doing it by hand isn't unbearable, but it would be interesting to see if a query engine written in a language with support for generators would be more pleasant:
class LimitOperator:
def run(self, rows_in_gen):
for rows_in in rows_in_gen:
yield rows_in[0:self.limit]
self.limit -= rows.len
if (self.limit == 0)
return
vectorized vs pipelined
Within each query pipeline there are two common styles of execution:
# pipelined
sum = 0
for index in 0..num_rows:
country = countries[index]
if country in ["France", "Germany"]:
price = prices[index]
if price > 0.99:
sum += price
return sum
# vectorized
indexes = 0..num_rows
indexes = [index for index in indexes if prices[index] > 0.99]
indexes = [index for index in indexes if countries[index] in ["France", "Germany"]]
return sum([price[index] for index in indexes])
In terms of performance on OLAP workloads, there are some tradeoffs:
- Pipelined code is able to keep values in registers which reduces memory traffic.
- The simple loops in vectorized style are more friendly to prefetching and simd.
But most evaluations find that both styles produce similar performance. Other concerns overwhelmingly dominate:
- In vectorized style it's easy to switch between multiple variants of each operator eg depending on the compression algorthim of the input vector. In pipelined style this would require too much branching per loop iteration.
- Pipelined style requires writing a compiler - paying the interpreter overhead per row is way too expensive (ref 9). Vectorized style can amortize the cost of the interprer overhead over an entire vector of values.
- Compilation latency with LLVM is too high for interactive usage. Systems which use LLVM typically also have to use an interpreter to get the query started while waiting for compilation to finish (eg ref 2.6). Umbra is a notable exception here - they wrote their own compiler backend with much lower latency (ref).
The result is that the pure OLAP systems generally use entirely vectorized style. And even the HTAP systems use vectorized style for scans over columnar data because adapting to different compression algorithms is a huge win over always decompressing before scanning.
The HTAP systems (HyPer/Umbra, SingleStore) use pipelined style after the initial scans. The argument is that vectorized style doesn't produce good performance for OLTP workloads, but I haven't seen a clear explanation of why. Certainly for row-based data layouts the advantages of vectorized style is reduced - each operator has to touch a lot of unrelated data, whereas pipelined style can keep each row in l1 or even in registers. But all these systems use pax layouts. Perhaps many OLTP queries simply don't return enough rows to fill a vector?
In vectorized style some combinations of operators can be very inefficient. Eg suppose we separate ... where 2023-01-01 <= date and date <= 2023-01-03 into separate filter-less-than and filter-more-than operators and combine the results with an and operator. Each of the filter operators would produce tons of rows, most of which would be discarded by the and operator. Whereas in pipelined style we would evaluate both conditions before yielding the row to the next operator. One solution is to build up a library of fused operators for common combinations (ref 3.3).
vectorized tips and tricks
Examples of adaptive operators that are easier in vectorized style:
- Scans operating over compressed data eg an equality test on a dictionary-encoded column doesn't have to decompress the data.
- String operations are often cheaper if all the strings in the column are known to be ascii-only.
- Reordering filters within a boolean expression so that the empirically cheapest/lowest-selectivity filter runs first.
- Skipping null checks when there are no nulls (similarly when the selection vector has no missing rows).
- For dictionary encoded data, scalar functions can be run only on the unique dictionary values.
Velox has a c++ template that takes a simple scalar function and produces a vectorized version with many of the above adaptive variants (ref 4.4.1). To avoid eagerly materializing nested types, the simple functions can operate over lazy reader/writer interfaces (ref).
There are a lot of implementation choices for filtering columns:
- Eager vs lazy materialization (make a new column vs returning a lazy view on the old column)
- For lazy materialization, represent the selection as a bitmap or a selection vector (a list of integer indexes)?
- For cheap operations over lazy vectors, in some conditions it might be cheaper to process all the input values rather than just the selected ones.
- For scans with multiple filters
where ... and ...: run each filter independently and combine the results, or run the second filter on the lazy vector produced by the first?
I found a few academic papers comparing these choices (ref, ref 5.1, ref 4.2) but no firm consensus. It seems like something I'll just have to benchmark in situ.
Worth noting though that both duckdb and velox use selection vectors and support lazy vectors. If you allow the selection vector to contain duplicates and out-of-order indexes then selection vectors can also represent dictionary-encoded data, which means that any fancy engineering done for one will benefit the other.
DuckDB also uses this values+selection format as a universal partially-decompressed format - if an operator doesn't have a specialized implementation for a given compression algorithm then it's fairly cheap to convert from most compression formats to values+selection without much copying.
questions
- Is it really worth materializing into row-based formats for hashtables etc, rather than storing an index into columns?
- How much compression ratio do we have to pay to preserve random access? Can we get close-to-random access on variable-length formats (eg RLE) by storing some small lookup accelarator?
- Is it ever worth compressing the output of an operator, rather than letting the tail ends of each pipeline devolve into raw values?
- In the duckdb/velox format, how to convert a selection vector on a more-nested column to a selection vector on a less-nested column? Is it reasonable to just binary search in the offsets column for each selected index? This seems like it would be cheaper with bitmaps.
- How should heterogenous data like sum types be handled in a columnar format? Is it worth using a selection vector next to the tag, or better to just use nullable columns for each of the possible payloads?
- Do vectorized interpreters perform worse than pipelined compilers on OLTP workloads even over column formats, or is this only true for row formats?
- When is it worth materializing a lazy vector? At some point the repeated cost of sparse memory access must outweigh the cost of copying data.
comments
Please feel free to email me with comments or corrections and I'll add them here.
Alex Monahan notes that:
- DuckDB supports sum types. It seems to use exactly the struct encoding I speculated on above. Looking at the impl here it seems like there isn't any compression of nullable columns in-memory, but that's probably fine since columns are only 2k rows - better to preserve simple random access instead. Not sure how nullable columns are compressed on disk, but I'd imagine that the space overhead could be kept to a minimum.
- DuckDB recently added the option for the optimizer to compress data at materialization points at the ends of pipelines. It seems to be a fairly significant win for some queries. If I'm reading it correctly, it isn't the same kind of columnar compression used elsewhere for vectors but instead a way to reduce the size of hash/sort keys.